写着玩-运行库
0x00 口胡
继续坚持。。。
0x01 入口函数和程序初始化
不管是在程序的开始还是程序的结束,main既不是最初被调用的,也不是最后被调用的,在main之前或之后,还可以有很多事情我们可以做,我们可以插入我们想要执行的代码。
操作系统在创建进程后,把控制权交到了程序的入口,这个入口往往是运行库中的某个入口函数。
举个例子:

GLIBC入口函数
glibc的启动过程在不同的情况下差别很大,比如静态的glibc和动态的glibc的差别,glibc用于可执行文件和用于共享库的差别,可以组合4种情况。下面关于Glibc和MSVCCRT的相关代码分析在不额外说明的情况下,都默认为静态/可执行文件链接的情况。其他情况自行举一反三
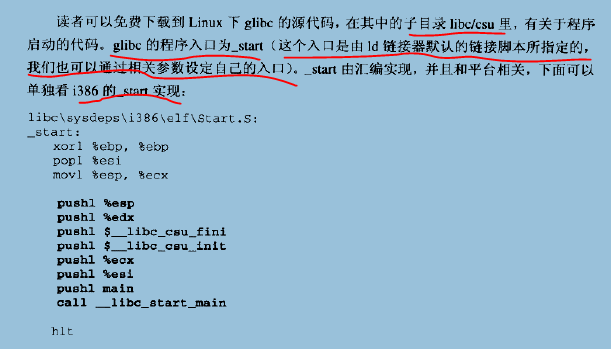
在介绍这段代码之前,我们首先要知道栈的布局是什么样的。
在前面我们介绍过,进程刚开始启动的时候,须知道一些进程运行的环境,最基本的就是系统环境变量和进程的运行参数。这些信息是需要在进程启动之前就需要提前给进程准备好的,一种常见的做法就是操作系统在进程启动前将这些信息提前保存到进程的虚拟空间的栈中(也就是VMA中的Stack VMA)。
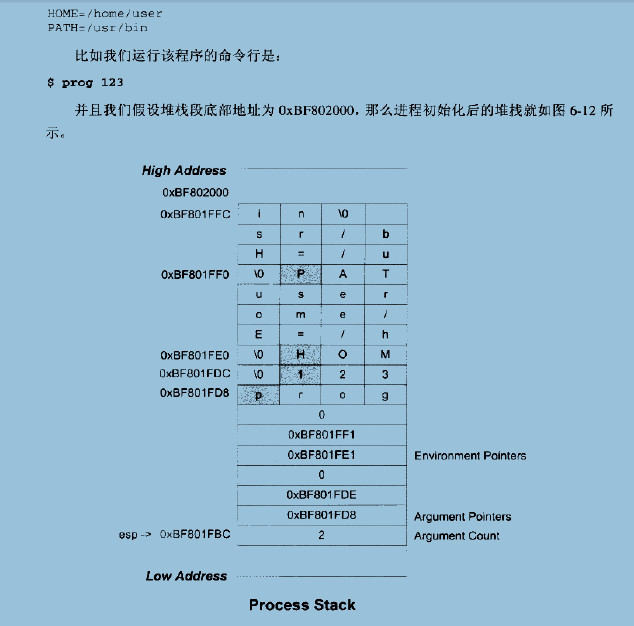


这里我们谈运行库,也就是说在glibc的start执行之前的栈结构就已经被初始化成了这个样子。
接下来看start:


环境变量:

start后时__libc_start_main:


对于libc_start_main中的BOUNDED_POINTERS__宏定义的说明:

接着看:

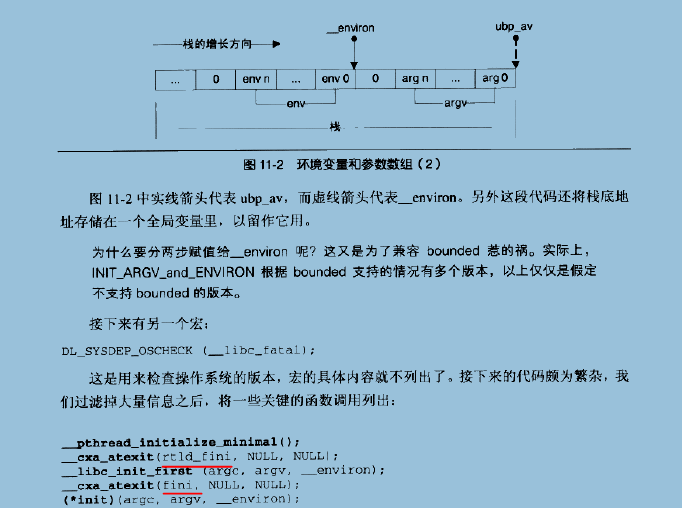


对于hlt指令的说明:

总结下,就是start开始,传入7个参数调用libc_start_main,在libc_start_main中,对各个参数进行解析,并将参数赋予一些具有具体意义的变量,以便后面使用;然后是调用一系列函数,在这些函数中,其中一个就是将main之后需要调用的函数提前注册一下,然后就是main了,main之后,调用exit,在exit中,会遍历链表,将上面注册的需要在面之后调用的函数调用,然后调用_exit(),_exit()中就是exit的系统调用,然后正常退出。
MSVC CRT入口函数
MSVC的CRT默认的入口函数名为mainCRTStartup:


对于alloca的说明:
接着说:

总结下,这个mainCRTStartup的总体流程就是:
- 初始化和OS版本有关的全局变量
- 初始化堆
- 初始化I/O
- 获取命令行参数和环境变量
- 初始化C库的一些数据
- 调用main并记录返回值
- 检查错误并将main的返回值返回
0x02 运行库与I/O
一个程序的I/O指代了程序与外界的交互,包括文件、管道、网络、命令行、信号等。更广义地讲,I/O指代任何操作系统理解为“文件”的事务。在操作系统层面上,文件操作也有类似于FILE的一个概念,在linux里,这叫做文件描述符(fd),而在Windows里,叫做句柄(handle)

给出FILE、fd、打开文件表和打开文件对象的关系图: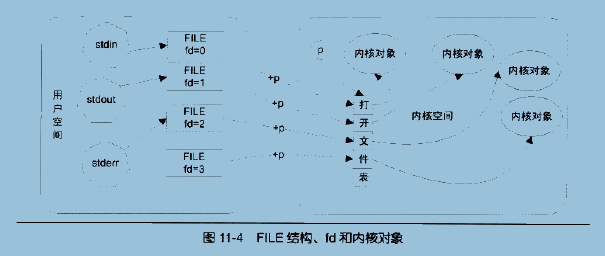
图中,内核指针p指向该进程的打开文件表,所以只要有fd,就可以用fd+p来得到打开文件表的某一项地址。stdin、stdout、stderr均是FILE结构的指针。
对于Windows的句柄,与linux的fd大同小异,不过Windows的句柄并不是打开文件表的下标,而是其下标经过某种线性变换之后的结果(如果变换是线性的话,可以通过多打开几个文件,来求解这种线性转换关系)。
所谓的I/O初始化,指I/O初始化函数需要在用户空间中建立stdin、stdout、stderr及其对应的FILE结构,使得程序进入main之后就可以直接使用printf、scanf等函数。
前面我们提到了MSVC CRT的入口函数,其中涉及到初始化部分。
对于堆的初始化:

可以看出,MSVC的堆初始化过程异常简单,仅仅调用了HeapCreate这个函数创建了一个系统堆。因此不难推测,MSVC的malloc函数必然调用HeapAlloc这个API,将堆管理的过程直接交给了操作系统。
对于I/O初始化:
我们先从总体上把握下I/O的初始化,MSVC的I/O初始化主要进行了如下几个工作:
- 建立打开文件表。
- 如果能够继承自父进程,那么从父进程获取继承的句柄。
- 初始化标准输入输出。
下面一个个来解释:
首先,每个进程都有一个自己的打开文件表,I/O初始化就是对这个打开文件表的初始化。

在初始化开始部分,会先声明一个数组,对应于图中的ioinfo * __pioinfo[64],这是一个指针数组,共有64个ioinfo结构的指针,这64个指针又分别指向ioinfo数组,书中说,每个数组的大小是32个ioinfo结构,所以这相当于一个二维数组。这里使用指针数组的原因是指针数组可以根据需要来去动态的申请空间,而不像二维数组那样,一上来就搞了64x32的大小,浪费。
这个指针数组毫无疑问就是打开文件表了,它的成员是ioinfo结构,给出这个结构体的定义:


MSVC的I/O初始化就是要构造这个二维的打开文件表。构造过程是在I/O初始化函数_ioinit中,该函数定义于crt/src/ioinit.c中。
首先,_ioinit函数初始化了__pioinfo数组的第一个二级数组:
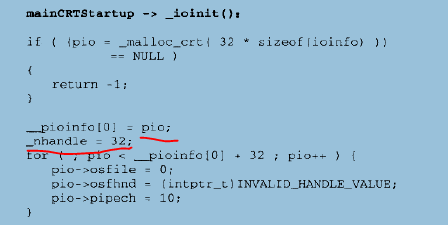
在这里_ioinit初始化了的__pioinfo[0]里的每一个元素为无效值,只起到一个占位的作用,其中INVALID_HANDLE_VALUE是Windows句柄的无效值,值为-1.
接下来,_ioinit的工作就是将一些预定义的打开文件给初始化,这包括两部分:

上图中说到,对于打开文件表的初始化,如果有继承自父进程的打开文件句柄,则需要把继承的句柄给填到自己的打开文件表中。如何获得从父进程继承的打开文件句柄呢?
可以使用API GetStartupInfo来获取继承的打开文件,GetStartInfo的参数如下:


有了GetStartupInfo结构以后,再根据上面的介绍,我们就可以得到继承的句柄了。而_ioinit函数也正是这么做的:

有了继承的句柄,下面就要往自己的打开文件表里填充了。
在填充之前,先是判断了一下直接的打开的文件表是否足以容纳所有的句柄:

然后要给打开文件表分配足够的空间以容纳所有的句柄:

可以看出,新分配的都是填入的无效数据,起到占位的作用。分配过后,填充就很容易了。


到这,I/O初始化算是真正完成了,所有的I/O函数都可以自由使用了。
我们知道,我们进行I/O操作时,都是把我们要进行I/O操作的对象当做文件来处理的,借由一系列的文件函数来达到I/O的效果。文件函数操作的是一种被称作FILE的结构。我们来看FILE结构和I/O的关系:
给出FILE结构定义:

图中说到通过_file字段可以访问到内部文件句柄表中的对应项,而通过前面的介绍,我们知道句柄值存储在ioinfo的osfhnd字段中且只有拿到句柄才能对相应的文件对象进行操作。
假设现在我们通过fopen()函数得到了一个FILE结构的指针,我们看下如何系统是如何通过这个FILE结构找到相应的句柄并进行文件操作的:
我们知道,句柄值(osfhnd)所在的ioinfo结构是处在__pioinfo这个二维数组中的,FILE结构中的_file的值,和此表的两个下标直接相关联。

这样,我们就知道FILE和句柄的对应关系了,有了句柄就可以进行操作了。
入口函数最重要的两部分-堆初始化和I/O初始化已经在上面谈到了。但是,入口函数只是冰山一角,它隶属的是一个庞大的代码集合,这个代码集合叫做运行库。
0x03 C语言运行库
C程序的运行,都需要C运行库(CRT)的支持。C语言运行库是一个庞大的代码集合,不管是VS中的VC/srt/src还是linux下的libc,都是大的要命,啃不动。
一个C语言运行库大致包含了如下功能:
- 启动与退出:包括入口函数及入口函数所依赖的其他函数等
- 标准函数:由C语言标准规定的C语言标准库所拥有的函数实现
- I/O:I/O功能的封装和实现
- 堆:堆的封装和实现
- 语言实现:语言中一些特殊功能的实现
- 调试:实现调试功能的代码
运行库的组成成分中,C语言标准库占据了主要地位。C语言标准库是C语言标准化的基础函数库,我们平时使用的printf、exit等都是标准库的一部分。标准库中定义了C语言中普遍存在的函数集合,我们可以放心的使用标准库中规定的函数而不用担心在将代码移植到别的平台时对应的平台上不提供这个函数。也就是说,只要支持C语言(常见的OS都是支持C的,很多都是C写的),那么这些函数就可以正常运行。
ANSI C的标准库由24个C头文件组成,与许多其他语言(如java)的标准库不同,C语言的标准库非常轻量,仅仅包含数学函数、字符/字符串处理,I/O等基本方面。


基本的就不介绍了,下面介绍下上面提到的变长参数和非局部跳转:
变长参数
变长参数的一个典型例子就是printf(),那么标准库中,在这种允许变长参数的函数内部是怎样去访问这些变长参数的呢?是使用几个宏-va_list、va_start()、va_arg():

变长参数的实现原理:
支持变长参数的C标准库函数一般调用方式都是cdecl的,变长参数的实现得益于C语言默认的cdecl调用惯例的自右向左压栈传递方式。
其实我们完全可以自己实现变长参数的支持,举个例子:
设想如下函数:
int sum(unsigned num,…);

这里,需要注意:

对于printf狂乱输出的问题,了解printf的,应该都知道用不好printf所带来的危险性。
回到前面说的va_list等宏的实现问题上,理所当然的很简单:

小扩展:变长参数宏的实现:


非局部跳转
这绝对是黑科技!!!

C语言运行库从某种程度上来讲是C语言的程序和不同操作系统平台之间的抽象层,它将不同的操作系统API抽象成相同的库函数。比如我们可以在不同的操作系统平台下使用fread来读取文件,而事实上fread在不同的操作系统平台下的实现是不同的,但作为运行库的使用者我们不需要关心这一点。
linux和Windows平台下的两个主要C语言运行库分别为glibc(GNU C Library)和 MSVCRT(Microsoft Visual C Run-time).

glibc
glibc的历史就不说了,没jb意思。事实上glibc出了C标准库之外,还有几个辅助程序运行的运行库,这几个文件可以称得上是真正的”运行库”,他们是/usr/lib/crt1.o、/usr/lib/crti.o、/usr/lib/crtn.o
glibc启动文件
crt1.o里面包含的就是程序的入口函数_start。
对于crti.o和crtn.o,这两个目标文件中包含的代码实际上是_init()函数和_finit()函数的开始和结尾部分,当这两个文件和其他目标文件顺序链接起来以后,刚好形成两个完整的函数_init()和_finit()。给出这两个文件的反汇编代码:
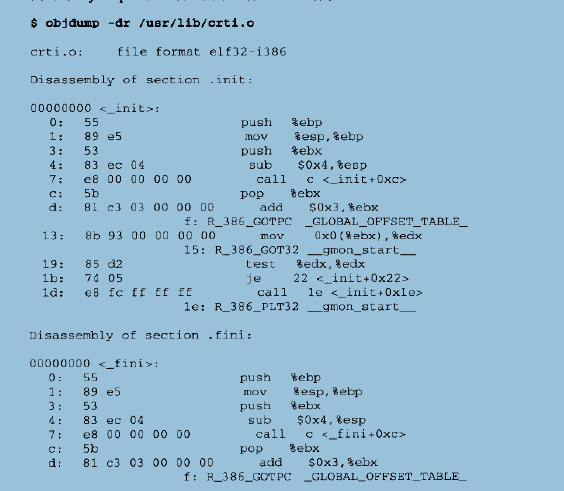
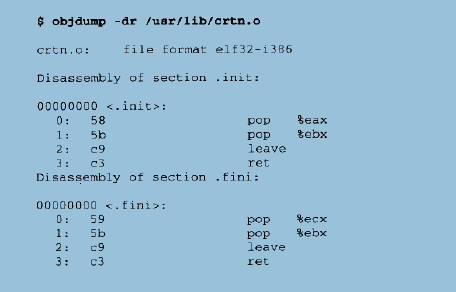

我们在前面提到过,crt1.o包含_start,在_start中,会调用libc_start_main(),在调用时,它向该函数传递了两个函数指针”libc_csu_init”和”__libc_csu_fini”,这两个函数负责调用_init()和_finit(),主要用于在main()函数之前执行的全局/静态对象构造和必须在main()函数之后执行的全局/静态对象析构。

取消默认的启动文件和C语言运行库

GCC平台相关目标文件

MSVC CRT
书上只是介绍了运行库的版本问题,以及如何通过命名方法来识别某个库支持什么。
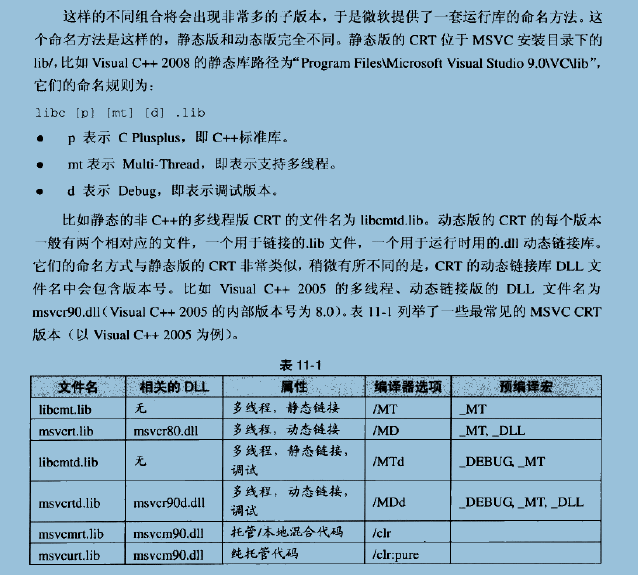
上图中所列的都是C语言的标准库,MSVC还提供了相应的C++标准库
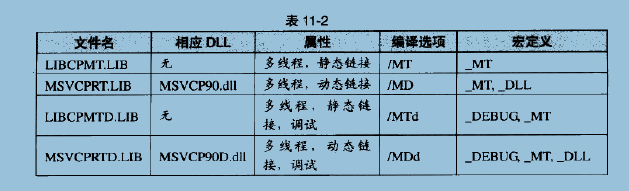
如果程序是用C++编写的,那么就需要额外链接相应的C++标准库,这里额外的有意思是,上图中的C++标准库里面包含的仅仅是C++的内容。当你在程序里包含了某个C++标准库的头文件时,MSVC编译器就认为该源代码文件是一个C++源代码程序
关于MSVC CRT的介绍,总之就是版本很多很复杂,用的时候要小心,其他就没有什么有营养的东西。

运行库与多线程
上面也说了,CRT是有单线程和多线程之分的,现有版本的C/C++标准是不支持多线程的,但主流的CRT都是有相应的多线程的功能的。
C语言运行库必须支持多线程环境。我们知道由于线程的切换和线程对于进程内存的所有数据都有访问权限的特性,就会由于在线程切换时由于访问进程内的同一资源而出现很多想不到的错误。由于多线程的普及,CRT为了支持多线程,解决这些错误,也是做了一些改进,包括使用TLS(线程局部存储)、加锁、改进函数调用方式。这些改进的核心原理就是在线程切换时,我们想要保护的线程共享数据是受到保护的。
TLS实现




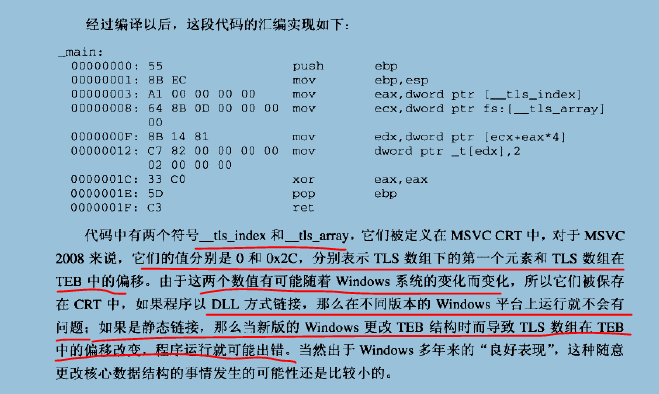





0x04 C++全局构造和析构
glibc全局构造和析构
我们在前面介绍start的时候,对于他的7个参数只是简单的列举了下,并没有详细介绍,这里详细介绍下。
_start->libc_start_main,_start在调用libc_start_main的时候是传递了7个参数的,其中传递的init函数指针指向的是__libc_csu_init函数,位于Glibc源代码目录的csu/ELF-init.c,给出:
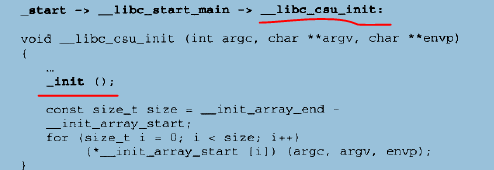
可以看出,调用了_init()函数,前面我们谈到过crti.o的_init()函数,这里__libc_csu_init里面调用的正是”.init”段,也就是说”.init”段中的代码就将在这里被执行。我们随意反汇编一个可执行文件的.init段:
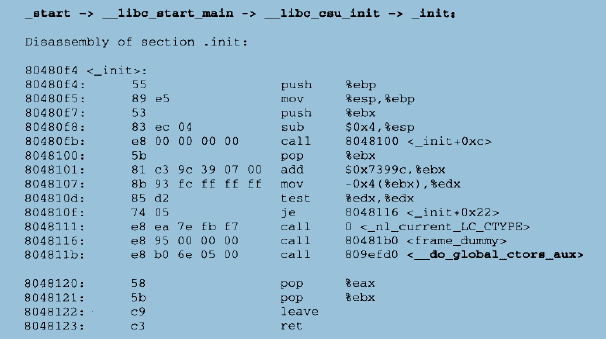

上面这段代码首先将CTOR_LIST数组的第一个元素当做数组元素的个数,然后将第一个元素之后的元素都当做是函数指针,并一一调用。很明显,CTOR_LIST里面存放的就是所有全局对象的构造函数的指针,那么接下来就开始研究CTOR_LIST这个数组了。
为了研究这个数组,我们给出一个示例代码:

对于每个编译单元(.cpp),GCC编译器会遍历其中所有的全局对象,生成一个名为_GLOBAL__I_Hw的函数,由这个函数负责本编译单元的所有的全局/静态对象的构造和析构,它的代码可以表示为:

先不管tcf_1这个函数。对于每个编译单元,如果它有全局/静态对象,那么他会生成GLOBALI_Hw这样的函数,然后他会在这个编译单元产生的目标文件(.o)的”.ctors”段里放置一个指针,这个指针就指向这个函数。
链接器在链接这些目标文件时,会将同名的段合并在一起,那么,理所当然的,每个目标文件的.ctors段将会被合并为一个.ctors段,其中的内容是各个目标文件的.ctors段的内存拼接而成。由于每个目标文件的.cors段都只存储了一个指针,指向那个用于构造和析构的函数,那么拼起来的.ctors段就是一个函数指针数组。
但是这个地址的数组现在是不可知的,这个数组的地址只有在链接(静态链接)的时候才能够真正确定下来,链接器是知道这个地址的,那么链接器是如何把它知道的这个关键地址告诉程序的呢?很简单,将这个地址存到某个地方不就行了,程序需要用到的时候就去这个地方取就行了。思想就是这么个思想,我们来看具体实现。
还记得在链接的时候,各个用户产生的目标文件的前后分别还要链接上一个crtbegin.o和crtend.o吗?这两个glibc自身的目标文件同样具有.ctors 段,在链接的时候,这两个文件的.ctors段的内容也会被合并到最终的可执行文件中。

解释下上图,链接器会将crtbegin.o中的.ctors段的起始地址定义成符号CTOR_LIST,这个符号是在最终链接形成的目标文件的符号段中是可以找到的,所以访问CTOR_LIST这个变量就可以得到这个数组的地址了。由于crtbegin.o中的.ctors位置的特殊性(总是第一个被合并),因此其起始地址就是所有.ctor段最终合并后的起始地址了。
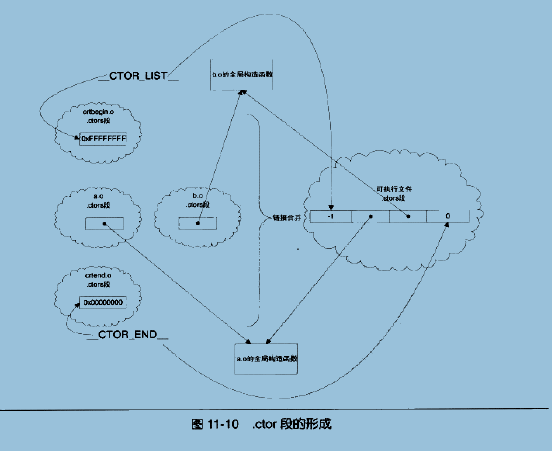
总结下,全局构造的实现,首先是在链接过程中,合并.ctors段得到最终的可执行文件中的.ctors段(就是一个全局构造函数指针数组),然后将这个指针数组的起始地址记录在变量(符号)CTOR_LIST中,链接完成,得到可执行文件。可执行文件执行,按照_start -> libc_start_main -> libc_csu_init -> _init -> do_global_ctors_aux的执行顺序来执行上述函数,而在do_global_ctors_aux函数中,直接访问变量(符号)CTOR_LIST来得到全局构造函数指针,从而一个个执行构造函数,完成全局构造。
在main前调用函数
知道的main前调用有:
- TLS回调
- .init段添加代码
- .ctors段添加函数指针

析构
讲完了构造,析构已经很显然了,无非就是在main执行后采用完全相反的顺序来执行析构了,早期的glibc和GCC确实是这样做的:


现在采用的做法是类似的,编译的时候每个编译单元的全局/静态对象会生成一个函数,这个函数有两个作用,一是执行构造函数,而是用at_exit把其相应的析构函数给注册一下,我们知道at_exit注册的函数会在main执行后的exit中被调用,而且满足先注册后调用的机制,所以很自然的被用于析构的实现。


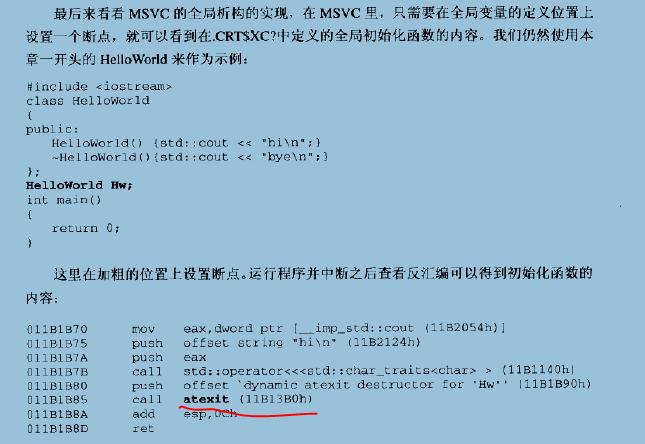
MSVC CRT的全局构造和析构



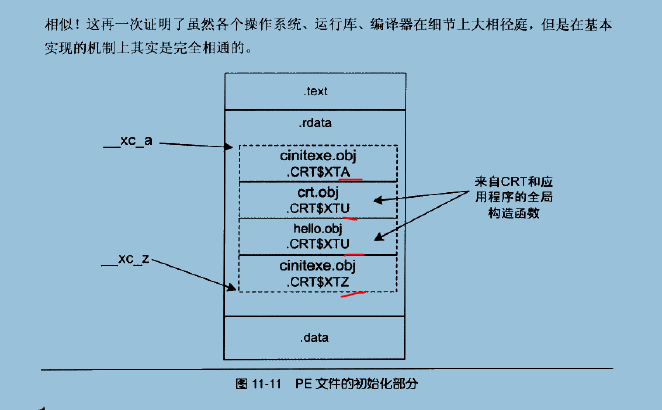
总结下,MSVC CRT的全局构造的大体实现机制与Glibc相似,在MSVC CRT中,在形成可执行文件时,两个全局变量xc_a和xc_z就被链接器初始化为数组的起始和结束地址,然后执行时,mainCRTStartup -> _inittern,在_inittern中,被循环遍历,执行全局构造。
在MSVC中同样可以修改段来得到main之前执行的权限
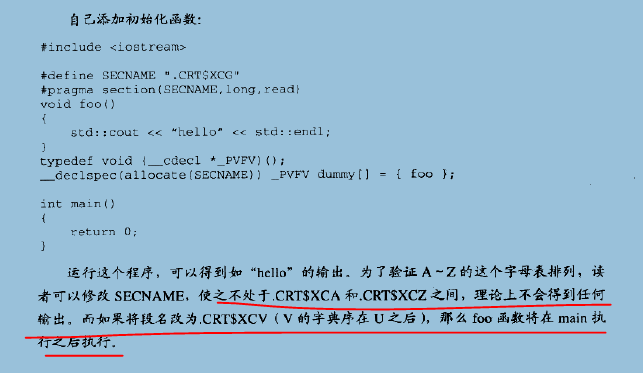
MSVC CRT析构
与glibc几乎相同:

0x05 fread实现
通过解析fread,进一步深入I/O
给出fread的函数声明:

我们知道,fread最终是通过Windows的系统API-ReadFile来实现对文件的读取的。给出ReadFile的函数声明:

可以看出他们在功能上看似完全相同,而且参数几乎一一对应。
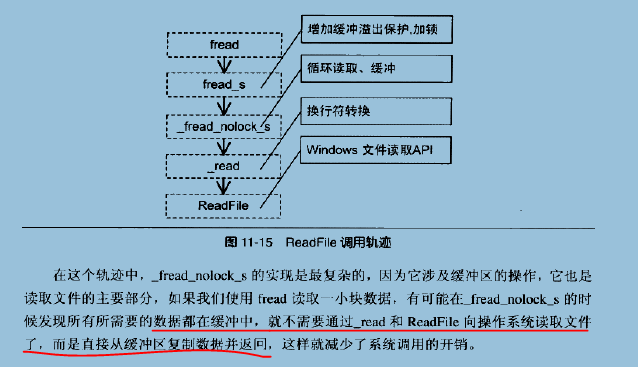
我们来看fread到ReadFile的中间到底干了什么。
对于glibc,fread的实现过于复杂,因此这里选择MSVC的fread实现。
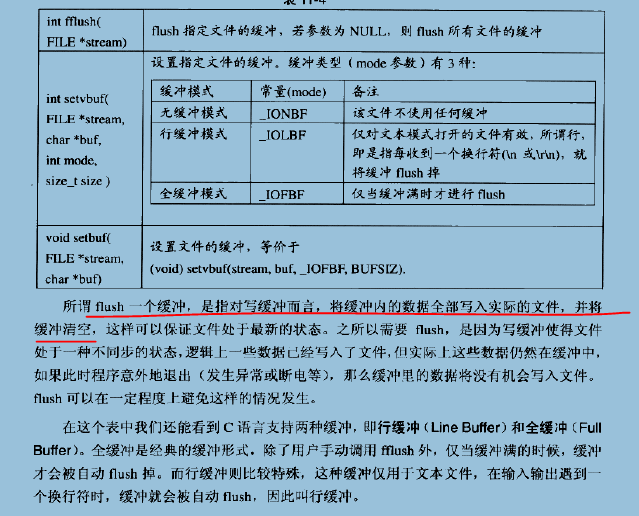
缓冲
提到文件操作,就不得不介绍缓冲,它是一种机制:

由于真正去操作文件是一件对OS来说非常费劲的事,所以要使用缓冲。当要读取数据的时候,首先看看这个文件的缓冲里有没有数据,如果有数据就直接从缓冲中取。如果缓冲是空的,那么CRT就通过操作系统一次性读取文件一块较大的内容填充缓冲,这样,如果每次读取文件都是一些尺寸很小的数据,那么这些读取操作大多都直接从缓冲中获得,可以避免大量的实际文件访问。
C语言标准库提供了几个与缓冲相关的基本函数,都是熟人:
fread_s
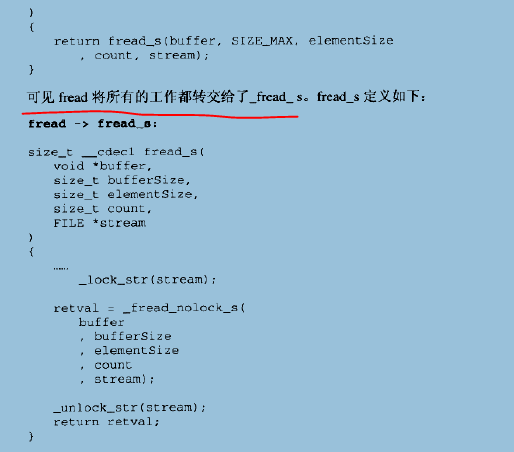
fread定义在crt/fread.c中,实际内容只有一行:




可以看出,文件的缓冲是在FILE结构中指出的,有缓冲的话,就会直接从文件缓冲中进行read,这里要把文件缓冲和buf分开。

是否使用文件缓冲以及使用文件缓冲的类型是在flag字段中记录的,下面的anybuf宏check是否使用文件缓冲也是根据flag中的这三个标志位来check的。

到这里,仅仅是确定了是否有文件缓冲,然后准备读数据,但此时还没有读,这里要分清两个读的过程,即从文件缓冲中读,读到最终的目的地buffer中和从真正的文件中读,读到文件缓冲中。此时,这两个读都没有发生,具体怎样读,分三种情况:
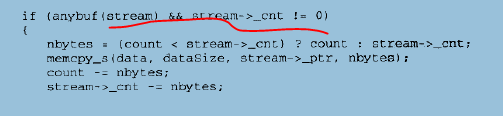

什么意思呢,就是有文件缓冲,并且缓冲不为空,就是说缓冲中有数据,则直接从文件缓冲中读数据读到最终目的地buffer中。
其中,nbytes代表这次要从文件缓冲中读取多少字节,在这里,nbytes等于还需要读取的字节数(count)与缓冲中剩余数据的字节数(stream -> _cnt)中较小的一个。接下来的一行使用memcpy_s将文件缓冲里ptr所指向的缓冲内容复制到data指向的最终目的地buffer中。接下来的5行就是更新FILE结构和局部变量由于这次操作而改变后的数据。

- 上面的1是缓冲不为空时的操作,当缓冲为空时(缓冲为空有两种可能,第一种是缓冲不为空,但读的数据大于缓冲的大小,直接通过1之后把缓冲读空了;第二种情况是虽然有缓冲,但缓冲本来就是空的),又分为两种情况:

对于情况1:

从文件中读整数个文件缓冲大小的数据(向上取整,在上面也可以看到这个读取的过程是一个while的循环过程,直到count(count是我们给定的我们想要从文件中读取的数据的大小)为0退出循环),也就是说这种情况下,每次都会读取文件缓冲大小的数据,而且不经过缓冲,直接从文件中读数据,然后把数据填到最终目的地buffer中,直到剩余的count的大小小于文件缓冲的尺寸,然后会执行情况2的代码:
对于情况2,即要读取的数据不大于缓冲的尺寸,那么仅需要重新填充缓冲即可:

反正到最后缓冲剩余的数据大小是>=0的。
可以看出。不管是哪种情况,只要是从文件中读数据,都是使用的同一个函数,那就是_read()函数。
_read()
_read函数主要负责两件事:
- 从文件读取数据
- 对文本模式打开的文件,转换回车符。

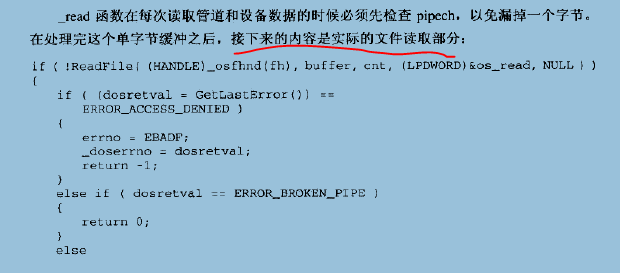

可以看出,_read就是封装了ReadFile,将真正的文件数据读到该读的地方去(文件缓冲或最终目的地buffer中),最后对返回值进行检查。
这样,fread的流程就算分析完了。
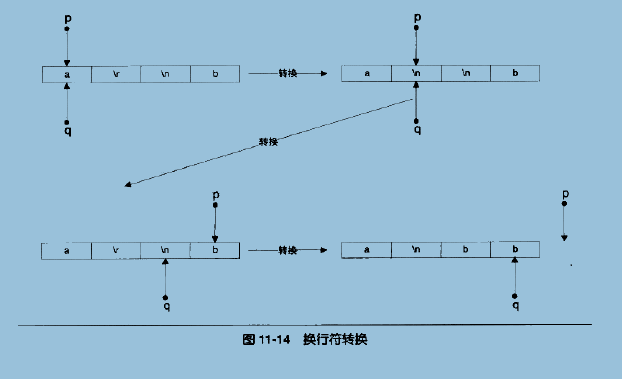
这里,还有一个遗漏,就是处理换行符的问题,上面提到的单字节缓冲就是用于处理换行的。我们知道ReadFile可以对管道或设备进行处理,前提是管道或设备以文本模式打开。





fread 流程总结
0x06 结
- 入口函数
- I/O初始化
- 文件缓冲
