写着玩-再战动态链接之windows
0x00 口胡
有幸去打了SSCTF的线下,结识了一些菊苣,不得不承认,他们对漏洞的发现速度过于惊人,当时就坐在旁边,一样的用ida看,可大大就是用短短的几小时就找出了漏洞点,并口述了利用方法,自己还在傻傻的撸汇编。。。、
每次打完比赛,有很多收获,知道自己的不足,前两个星期一直在ctftime刷pwn题,对漏洞的发现与利用更加的迅速和效率了,但是对于大量代码的程序,自己的漏洞挖掘能力还是相当不行,主要是一看这么多汇编,硬看的话都得看半天,而且上下文容易忘记,导致自己没有太大信心去挖这里面的漏洞,所以还是得加强自己读码的能力,什么时候能练到一目十行的地步,感觉漏洞的定位应该就很迅速了。。。
想了下,还是基础不行,各种机制不熟,阅读块代码的能力很弱,都是一行行的读,太慢。。。
所以,还是得静下心来巩固基础,了解熟悉各种机制、底层细节,才能在读码上更加得心应手,所以又想起了这本被我遗忘在角落中的自我修养一书。。。
0x01 DLL
根据题目,毫无疑问,本篇重点就是DLL了,相当于Linux下的共享对象(so),DLL的扩展名不一定是DLL,也有可能是别的,比如.ocx(OCX控件)或是.CPL(控制面板程序)
像一些基本概念,什么基址,相对地址啊、导入导出啊什么的,就不多谈了。。。
一个DLL在不同的进程中拥有不同的私有数据副本,就像我们前面提到过的ELF共享对象一样,so可以实现代码段地址无关,但DLL并不是,只是在某些情况下可以被多个进程间共享。当然,windows允许将DLL的数据段设置成共享的,即任何进程都可以共享该DLL的同一份数据段。很多时候比较常见的一种做法就是将一些需要进程间共享的变量分离出来,放到另一个数据段中,然后将这个数据段设置成进程间可共享的。
declspec(dllexport)表示该符号是从本dll导出的符号,declspec(dllimport)表示导入
一些使用dll时应当注意的东西:
- 对于从其他dll中导入的符号,需要用”declspec(dllimport)”显式地声明某个符号为导入符号,这与ELF中的情况不一样,ELF就不需要。
- 当我们使用某个dll时,需要使用链接器将需要使用dll的的obj文件和该dll对应的lib文件链接在一起产生一个可执行文件。这里的.lib文件,我们在静态链接的时候,介绍过,.lib文件是一组目标文件的集合,在动态链接里面这一点仍然没有错,在动态链接中,.lib文件并不真正包含.c文件的代码和数据,而是用来描述.dll的导出符号,它包含了其他目标文件链接.dll文件时所需要的导入符号以及一部分”桩”代码,又称”胶水代码”,这样的.lib文件又被称为导入库
- 模块定义文件.def可以控制输出文件的默认堆大小、输出文件名、各个段的属性,默认堆栈大小、版本号等,具体参照MSDN关于.def文件的介绍。
- 显示运行时链接三大函数:LoadLibrary(),GetProcAddress(),FreeLibrary()
0x02 符号导出导入表
导出表

在PE中,谈到导入导出时,经常把函数和符号混淆在一起,因为PE绝大部分时候只导入导出函数,很少导入导出变量。
又要强势撸一把PE结构姿势了。。。

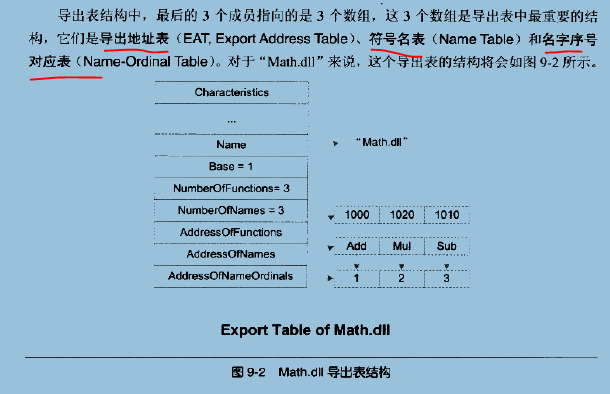
这3个数组中,前两个很直观,第一个叫导出地址表EAT,它存放的是各个导出函数的RVA,比如第一项是0x1000,它是Add函数的RVA,第二个表是函数名表,它保存的是导出函数的名字,这个表中,所有的函数名是按照ASCII顺序排序的,以便于动态链接器在查找函数名字时可以速度更快(二分查找)
还有一个序号表,对应着序号导入的方式,比较节省空间;函数名表对应着字符串导入的方式。序号的导出方式为:一个导出函数的序号就是函数在EAT中的地址下标加上一个Base值(也就是IMAGE_EXPORT_DIRECTORY中的Base,默认情况下它的值是1)
举个例子,Mul的RVA是0x1020,它在EAT中的下标是1,加上一个Base值1,Mul的导出序号为2。若一个模块A序号方式导入了某个函数,则这个模块A中的导入表就不会保存函数名,而是保存函数的序号,当动态链接时,当寻找一个函数的地址时,只需要根据模块A的导入表中保存的序号,减去IMAGE_EXPORT_DIRECTORY中的Base字段值,得到一个下标,这个下标就是该函数在EAT表中的index值,从而找到地址。
序号的导入毕竟是为了适应以前内存成本高的情况,省去了函数名查找过程,节省了保存函数名表的内存空间,但是,函数的序号可能会变化,因为dll是会更新的,针对序号变化,我们可以手工指定dll的导出序号,但是还是麻烦。
现在硬件条件较好,所以一般采用函数名导入,解决了序号导入的不稳定问题,而且便于理解和程序调试。
但是序号导出方式还是保留着的,还是可以用的。而且一个导出函数肯定有一个序号值(序号值是肯定有的,因为函数在EAT的下标加上Base就是序号值),但是可以没有函数名。

就是函数名表确定位置->序号表得到index->根据index查地址表。

EXP文件
此EXP非彼EXP。。。

导出重定向

导入表
在ELF中,.rel.dyn和.rel.plt两个段中保存了该模块所需要导入的变量和函数的符号,以及所在的模块等信息,而.got和.got.plt则保存着这些变量和函数的真正地址。windows简单粗暴,就叫导入表。

别忘了有两种导入方式

导入表的核心-IAT



化,使得接下来的对该DLL的调用速度与普通方式载入的DLL的速度相差无异。这个有点像ELF的PLT的作用
在不考虑PLT的情况下,IAT相当于GOT。
我们知道,函数调用分为内部调用和外部调用之分,在windows中,对于内部调用,编译器产生的都是直接调用指令;而对于外部调用,产生的是间接调用指令。二者都能达到正常调用的目的。对于windows,区分外部和内部,靠的是一个扩展属性”declspec(dllimport)”,一旦一个函数被声明为”declspec(dllimport)”,那么编译器就知道它是外部导入的,就会产生间接调用指令,call ptr [xxxx]这种,而xxxx指向该函数在IAT中的位置,相当于GOT间接跳转,所以外部调用可以正常实现。
接下来是内部调用,对于内部调用,使用的是直接调用指令,即call xxxx这种,但是,如果没有使用那个扩展属性,编译器同样会将外部导入函数处理成内部调用的形式,这样的话,那么就会发生错误,因为内部调用是在链接时就会确定地址的,也就是说在程序装载进行动态链接之前,xxxx就是一个确定的地址,而且不存在重定位,所以如果放任不管,它是找不到要调用函数的入口点的,这样就一定会出错了。
Windows的解决方法就是桩代码了。对于非导入的内部调用,在静态链接时,即可重定位到正确的调用位置,而对于无法找到正确位置的内部调用,将其识别为导入内部调用,即后面的xxxx指向的其实是一段桩代码,而这段桩代码其实就是一段jmp指令,jmp到为该函数。。。球都麻袋,刚才验证了下,发现上面的解释不对,重新解释
首先,在静态链接的过程中,静态链接器即可确定导入了那几个dll,然后他会根据这些dll的导出表生成一个导入表,导入表中包含这些dll的所有导出函数,但是真正在程序中用到几个函数,链接器是不管的,对于用户自定义的函数,在静态链接时,函数调用语句直接被重定位到相应的位置,而如果是非自定义函数,则会遍历导入表,看是否是导入函数,如果既不是自定义也不是导入函数,则会直接报错,如果是导入函数,又分两种情况,一种是带扩展属性”__declspec(dllimport)”的,一种是不带的,但首先我们得知道,IAT在动态链接时是会被刷成正确的函数地址的,也就是说我们在静态链接时只需要将导入函数的调用指令最终指向IAT就算大功告成了,这点在ELF中也类似,ELF为了实现延迟绑定,提高效率,普遍采用PLT机制,即call指令后面跟的是该函数的PLT槽位置,然后通过PLT桩代码跳到GOT,实现正确调用。我们回过头来看windows,带扩展属性的,产生间接调用指令,不带的,产生直接调用指令,那二者怎么达到相同的目的呢?很简单,一个用桩代码,一个不用呗。对于带扩展属性的,是间接调用指令,不用桩代码,call ptr [xxxx]中的xxxx在静态链接时就会指向该函数的IAT槽位置,实现正确调用;不带扩展属性的,静态链接器产生直接调用指令call xxxx,xxxx是桩代码所在位置,借由桩代码的jmp,来跳到IAT槽,从而实现正确调用。
上面的解释看似是解决了这个问题,但是这个桩代码就处于一个很尴尬的境地,我们知道链接器是不产生指令的,那桩代码靠谁产生呢?靠编译器,我也想过,大家来仔细想一想,编译器是将一个.c文件编译成.obj文件,这个.c文件的源码可能引入三种调用,第一种,在.c文件中已经定义了的函数的调用,这种调用在编译成.obj文件时即可用相对偏移调用的形式将call后面的地址确定;第二种,在其他.c文件编译成的.obj文件中定义了的函数调用,这种调用是需要重定位的,将重定位信息放到重定位表中,产生call xxxx指令,然后编译器就不管了;第三种,就是导入函数调用,其实在编译器看来,第二种和第三种是没有区别的,所以对于第二种和第三种,编译器是做的相同的工作,产生call指令,放置重定位信息,然后不管了。可能有的同学回问,为什么编译器在遇到第二种和第三种时,不进行导入表的扫描呢,然后不就可以把第二种和第三种分开了吗?但是有个问题限制了这样做,限制了第二种和第三种的区分。 因为只有一个.obj文件,导入表的信息不全,即无法确定其他.obj文件所依赖的.dll,也就是说只有在静态链接时,当所有的.obj文件都聚齐后,才可以召唤神龙,不,是才可以确定最终的导入表信息,这就使得导入表的扫描只有在静态链接时才能做,编译器无法做,即编译器无法区别第二种和第三种调用,也就无法产生桩代码。而链接器可以扫描全局导入表,即可以在无法将函数调用重定位到正确的地址时,即判断到该函数调用并不是第二种时,链接器就会进行是不是第三种的判断,如果连第三种都不是,则就报错,是第三种的话,还有缓和的余地,但是,又尴尬了,链接器在确定了是第三种调用后,它只能干瞪眼,也就是说他并不能产生桩代码,只能够将call后面的地址重定位到某个地方。
到这里,已经基本理清,就是说,所有的函数调用指令一般都是直接调用指令(大多数情况)对于前两种,静态链接器可以确定call后面的地址(第一种由编译器确定,第二种由链接器重定位),对于第三种,链接器只能对call后面的地址码进行重定位操作,至于重定位到哪,下面再谈。
分析到这,我们来看windows具体怎么做的,怎么解决的这个问题。答案就是,桩代码是由dll产生的,更深入的说,桩代码来自产生dll文件时伴随的那个LIB文件,即导入库。这里要区分一下导入库和导入表,导入库是dll文件伴随产生的,导入表一般是exe文件中的。编译器在产生导入库时,同一个导出函数会产生两个符号的定义,比如对于函数Add来说,它在导入库中有两个符号,一个是Add,另外一个是impAdd,这两个函数的区别是,Add这个符号指向Add函数的桩代码,而impAdd指向Add函数在IAT中的位置。所以当我们通过__declspec(dllimport)来声明导入函数
接着上上一段谈,当编译器遇到declspec(dllimport)时,编译器可以很明显的知道这是第三种调用,拿Add举例,当Add使用declspec(dllimport)时,当.c中调用Add时,编译器会产生类似call ds:[impAdd]的指令;当Add不使用declspec(dllimport)时,当.c调用Add时,编译器会产生类似call ds:[Add]的指令,,然后编译器就算干完活了,交给链接器进行重定位,链接器会首先在链接文件中找,找不到时,即确定不是第二种调用时,就会去.lib文件中找(这正好解释了为什么链接时需要.lib文件了),lib中是有符号信息的,然后链接器就会就根据相应的符号在lib中进行查找(Add或impAdd),找不到就报错,找到就会在导入表中存储上相应的符号,符号在带不带declspec(dllimport)时都是一样的,只是会将不同的符号记录成不同的重定位信息,以便于在将call指令进行重定位,然后就完事了。在运行时,IAT会被刷新前面介绍过,foo会被重定位为桩代码,即call ds:[foo]->jmp foo->foo的执行,而impAdd是直接定位到函数在
上面一段可以不看,经过一番调试与挣扎,决定还是按书上的思路来进行理解,按照书上的说,使用declspec(dllimport)时,会在导入表中产生符号imp前缀修饰的,不使用,直接使用原来的名字,以便于跟.lib文件中的两个符号进行相应的匹配,然后会在导入表中产生相应的符号项(imp或不带),但二者在导入表中只能有一个,即对应是否使用。在导入表中产生完相应的IAT项后,静态链接器会将call指令都重定位到相应的符号在IAT中的位置,即call后面的地址码指向该符号在IAT中的唯一项(带imp或不带),这样只是在装载时会有所不同,我们知道,装载时,IAT会进行相应的刷新,那么,根据书理解,IAT中带__imp前缀的项的内容会被刷新为函数的入口地址,而不带前缀的项会被刷新为桩代码的地址(dll中是有桩代码的),由桩代码实行间接跳转。
两种导入方式都支持,但推荐使用__declspec(dllimport)进行导入。就这样,有点太钻牛角尖了。。。
0x03 DLL优化
重定基地址
对于基址加载问题,Windows PE采用了一种与ELF不同的办法,叫做装载时重定位,即对每个绝对地址引用都进行重定位。其实就是,每个绝对地址引用+一个偏移,偏移是(|预期基地址-真正加载基地址|)。

改变默认基地址
当然我们在链接生成某DLL时,可以手动指定该DLL的基地址

当然,对于已经生成的DLL,我们还是可以指定基地址

对于一些系统DLL,Windows在进程空间中专门划出一块0x70000000~0x80000000区域,用于映射这些常用的系统DLL,省去了装载时重定基地址的麻烦。
序号
有序号导出,那么,相应的就会有序号导入

序号导入比函数名导入快一点,但是在现在的硬件条件下,并不推荐,但是可以用于软件的混淆,试想,如果分析的函数都是序号,那也挺恶心的。
导入函数绑定
试想,每次运行程序,其所依赖的DLL都会被装载,而且还要进行装载时的重定位操作。但是,大多数情况下,DLL会以同样的顺序被装载到同样的内存地址,所以DLL的导出符号地址这时都是不变的,这样的话,每次程序运行时都要重新进行符号的查找、解析和重定位这个过程就显得很多余。
提供一个合理的思路–将这些导出函数的地址保存到模块的导入表中,这样可以省去每次启动时的符号解析过程。这种优化叫做DLL绑定。有具体的工具支持这种绑定:
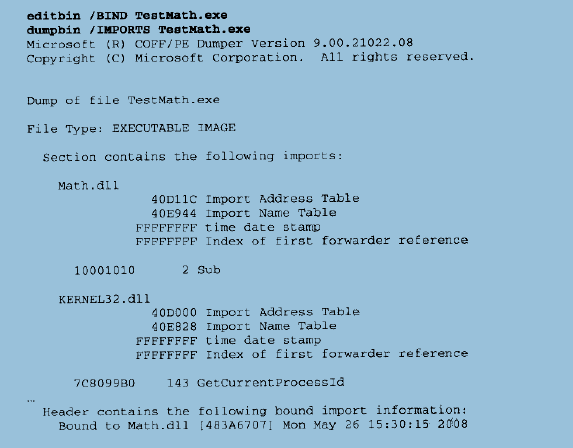
具体原理为:

但是,绑定也有失效的时候:
- 被依赖的DLL更新导致DLL的导出函数地址发生变化;
- 被依赖的DLL在装载时发生重定基址,导致DLL的装载地址与绑定时不一致。
下面提出解决方案:
对于第一种情况的失效,很好解决,加一个前后比对的东西就行。PE的做法为,当对程序进行绑定时,对于每个导入的DLL,链接器把DLL的时间戳(Timestamp)和校验和(Checksum,比如MD5)保存到被绑定的PE文件的导入表中。在运行时,Windows会核对将要被装载的DLL与绑定时的DLL版本是否相同,并且确认该DLL没有发生重定基址(这是第二种失效的解决)。没有变化,不用解析;若有变化,正常进行符号解析。

0x04 DLL HELL
DLL容易发生不兼容问题,称为DLL HELL(DLL 噩梦)。
解决DLL HELL的方法:


对于Manifest文件:


0x05 小结

