密码系列12-消息认证机制
0x00 口胡
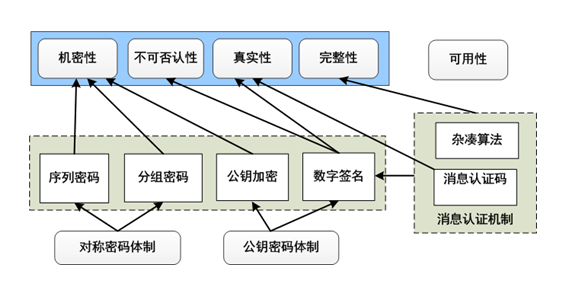
截至目前为止,我们已经讨论了对称密码体制和公钥密码体制,对称密码体制主要用于保护数据的机密性,公钥密码体制分为公钥加密和数字签名,其中公钥加密主要用于保护数据的机密性,数字签名用于保护数据的不可否认性和真实性,但是这两大体制并不能提供对数据完整性的保护,这时就需要消息认证机制来承担起对数据完整性的保护。
0x01 消息认证机制概述
消息认证是一个过程,用以验证接收消息的完整性(未被篡改、插入、删除)。认证是一个过程,消息认证机制有消息认证码(MAC)和散列函数(hash)两大类。
消息认证码
消息认证码(MAC)是指消息被一密钥控制的公开函数作用后产生的、用作认证符的、固定长度的数值,也称为密码校验和。
数据认证算法是最为广泛使用的消息认证码,已作为FIPS Publication(FIPS PUB 113)并被ANSI作为X9.17标准。
数据认证算法基于CBC模式的DES算法,其初始向量取为零向量,其中最后一个分组不够64比特的话,可在其右边填充一些0,然后按以下过程计算消息认证码:
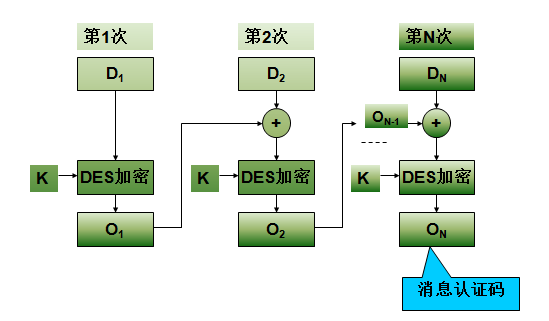

消息认证码的使用流程
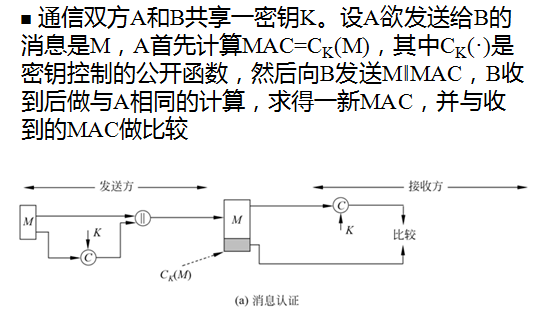
消息认证码的安全性是基于仅通信双方知道密钥K这个前提的。如果仅收发双方知道K,且B计算得到的MAC与接收到的MAC一致,则这一系统就实现了以下功能:
- 完整性:接收方相信发送方发来的消息未被篡改,这是因为攻击者不知道密钥,所以不能够在篡改消息后相应地篡改MAC,而如果仅篡改消息,则接收方计算的新MAC将与收到的MAC不同。
- 真实性:接收方相信发送方不是冒充的,这是因为除收发双方外再无其他人知道密钥,因此其他人不可能对自己发送的消息计算出正确的MAC。
散列函数
散列函数H是一公开函数,用于将任意长的消息M映射为较短的、固定长度的一个值H(M),称函数值H(M)为杂凑值、杂凑码或消息摘要。杂凑值是消息中所有比特的函数,即改变消息中任何一个比特或几个比特都会使杂凑码发生改变,这是保证消息完整性的最基本的要求。
散列函数的目的是为需认证的数据产生一个“指纹”。为了能够实现对数据的认证,散列函数应满足几个要求:
- 函数的输入可以是任意长。
- 函数的输出是固定长。
- 已知x,求H(x)较为容易,可用硬件或软件实现。
- 已知h,求使得H(x)=h的x在计算上是不可行的,这一性质称为函数的单向性,称H(x)为单向散列函数。
- 已知x,找出y(y≠x)使得H(y)=H(x)在计算上是不可行的。
- 找出任意两个不同的输入x、y,使得H(y)=H(x)在计算上是不可行的。
以上6个条件中,前3个是散列函数能用于消息认证的基本要求。第4个条件(即单向性)则对使用秘密值的认证技术极为重要。
散列函数结构
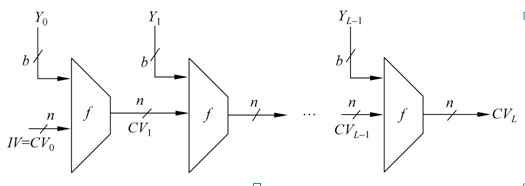
目前使用的大多数散列函数其结构都是迭代型的,如图所示。其中函数的输入M被分为L个分组Y0,Y1,…,YL-1,每一个分组的长度为b比特,最后一个分组的长度不够的话,需对其做填充。
对上图的说明:IV = 初始值;CV = 链接值;Yi = 第i 个输入数据块;f = 压缩算法;n = 散列码的长度;b = 输入块的长度
0x02 几种常用的杂凑算法
1. MD5杂凑算法
由Ron Rivest(没错,就是RSA的那个R)于1992年4月公布(RFC 1320,1321)称为MD5。
算法的输入为任意长的消息,分为512比特长的分组,输出为128比特的消息摘要。
MD5算法流程
明文分组
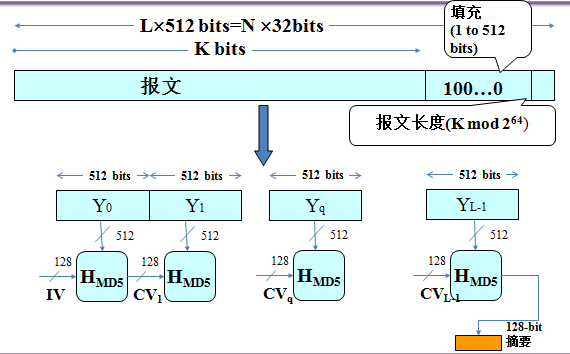
对明文的处理分以下两步:
- 对消息填充,使得其比特长在模512下为448,即填充后消息的长度为512的某一倍数减64,留出的64比特备第2步使用。
步骤1是必需的,即使消息长度已满足要求,仍需填充。例如,消息长为448比特,则需填充512比特,使其长度变为960,因此填充的比特数大于等于1而小于等于512。
填充方式是固定的,即第1位为1,其后各位皆为0。 - 附加消息的长度用步骤1留出的64比特以little-endian方式来表示消息被填充前的长度。如果消息长度大于2^64,则以2^64为模数取模。
Little-endian方式是指按数据的最低有效字节(byte)(或最低有效位)优先的顺序存储数据,即将最低有效字节(或最低有效位)存于低地址字节(或位)。相反的存储方式称为big-endian方式。
这两步执行完后,消息的长度为512的倍数(设为L倍)。
将消息表示为分组长为512的一系列分组Y0,Y1,…,YL-1,而每一分组又可表示为16个32比特长的字,这样消息中的总字数为N=L×16,因此消息又可按字表示为M[0,…,N-1]。
具体的对明文的处理流程(函数Hmd5)
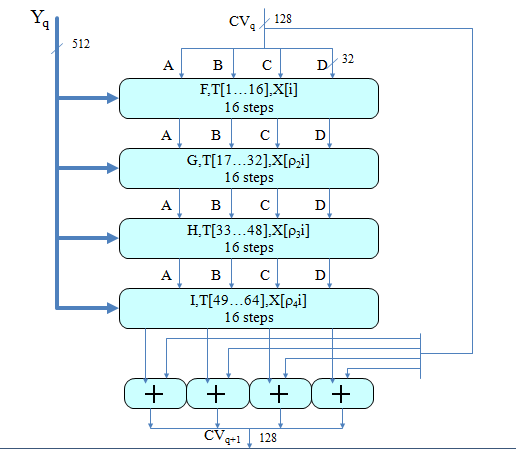
这里使用128比特长的缓冲区以存储中间结果和最终杂凑值,缓冲区可表示为4个32比特长的寄存器(A,B,C,D),每个寄存器都以little-endian方式存储数据,其初值取为(以存储方式) A=01234567,B=89ABCDEF, C=FEDCBA98,D=76543210,实际上为67452301,EFCDAB89,98BADCFE,10325476。
函数Hmd5的总体概述:

每轮中压缩函数Hmd5的具体细节

上述过程用图形表示为:
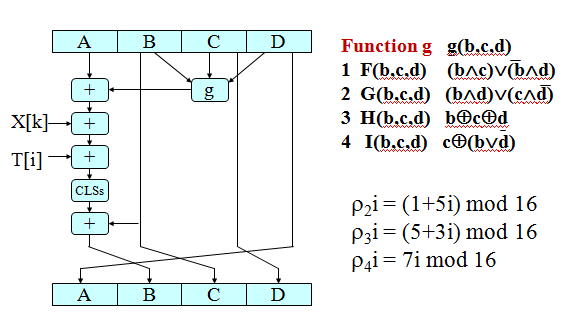
对上图的补充说明:
T[i]为表T中的第i个字,+为模2^32加法。其中∧,∨,-,分别是逻辑与、逻辑或、逻辑非运算
对于每步中左循环移位的位数s,给出s表:
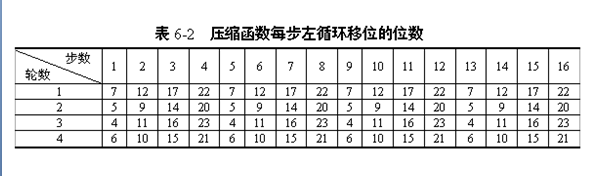
- 对于图中的x[k],给出如下说明:

流程总结:
- 总流程图:
总流程有4轮,除一些细节外每轮大致一样,每轮有16步
- 每步的操作:
对MD5的攻击
我们由生日悖论问题引入对MD5的攻击方法。
生日悖论是考虑这样一个问题:在k个人中至少有两个人的生日相同的概率大于0.5时,k至少多大?
这个问题很简单,学过排列组合的都能很容易计算出来。给出计算方法:

在散列函数中:

就是我们通常所说的散列函数的碰撞问题,上面的图中直接给出了碰撞结论,即若散列函数的输出有2^m个可能的话,那么对于2^(m/2)个随机输入,至少有两个输出相同的概率是大于0.5的,那么运用这个结论,我们就可以对md5实施生日攻击。
对生日攻击的流程:

上图中提到了对消息的变形的概念。将一个消息变形为具有相同含义的另一消息的方法有很多,例如对文件,敌手可在文件的单词之间插入很多“space-space-backspace”字符对,然后将其中的某些字符对替换为“space-backspace-space ”就得到一个变形的消息。
md5生日攻击的成本:上述攻击中如果杂凑值的长为64比特,则敌手攻击成功所需的时间复杂度为O(2^32)。对于MD5而言,MD5作为128比特长的杂凑值来说,找出具有相同杂凑值的两个消息需执行O(2^64)次运算。
插一下:我国山东大学王小云教授(2004)提出的攻击对MD5最具威胁。对于MD5的初始值IV,王小云找到了许多512位的分组对,它们的MD5值相同。所以必须寻找新的杂凑算法,以使其产生的杂凑值更长,且抵抗已知密码分析攻击的能力更强。下面要介绍的SHA即为这样的一个算法。
2. SHA1杂凑算法
安全杂凑算法(secure hash algorithm, SHA)由美国NIST设计,于1993年作为联邦信息处理标准(FIPS PUB 180)公布。SHA其结构与MD5算法非常类似。
算法的输入为小于2^64比特长的任意消息,分为512比特长的分组,输出为160比特长的消息摘要
SHA1流程
毕竟上面介绍了MD5,我们就相较于MD5来看,看看SHA1有什么不同
明文的分组
- 对消息填充与MD5的步骤1完全相同。
- 附加消息的长度与MD5的步骤2类似,不同之处在于以big-endian方式表示填充前消息的长度。
缓冲区的初始化
相对于MD5而言,SHA1缓冲区初始化算法使用160比特长的缓冲区存储中间结果和最终杂凑值,缓冲区可表示为5个32比特长的寄存器(A, B, C, D, E),每个寄存器都以big-endian方式存储数据,其初始值分别为A=67452301,B=EFCDAB89,C=98BADCFB,D=10325476,E=C3D2E1F0。
具体的对明文的处理流程(函数Hsha)
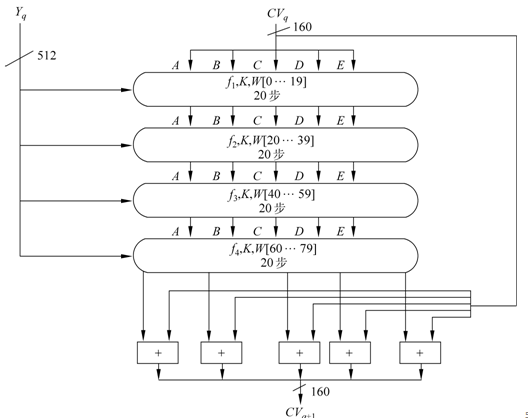
对上图的说明:
以分组为单位对消息进行处理每一分组Yq都经一压缩函数处理,压缩函数由4轮处理过程构成,每一轮又由20步迭代组成。4轮处理过程结构一样,但所用的基本逻辑函数不同,分别表示为f1,f2,f3,f4。
每轮的输入为当前处理的消息分组Yq和缓冲区的当前值A,B,C,D,E,输出仍放在缓冲区以替代A,B,C,D,E的旧值,每轮处理过程还需加上一个加法常量Kt,其中0≤t≤79表示迭代的步数。80个常量中实际上只有4个不同取值,下面给出Kt的取值表:

其中 [x] 为x的整数部分。
第4轮的输出(即第80步迭代的输出)再与第1轮的输入CVq相加,以产生CVq+1,其中加法是缓冲区5个字中的每一个字与CVq中相应的字模2^32相加。
输出消息的L个分组都被处理完后,最后一个分组的输出即为160比特的消息摘要。
每轮中压缩函数的具体细节
给出每轮每步的流程框架图:
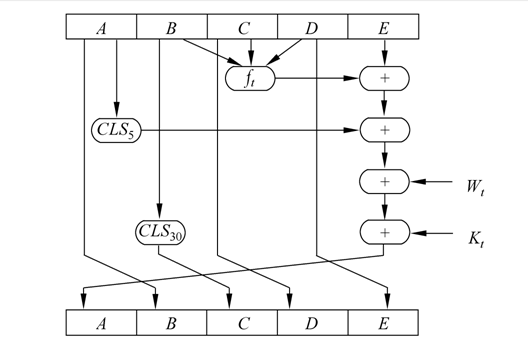
对流程的解释说明:

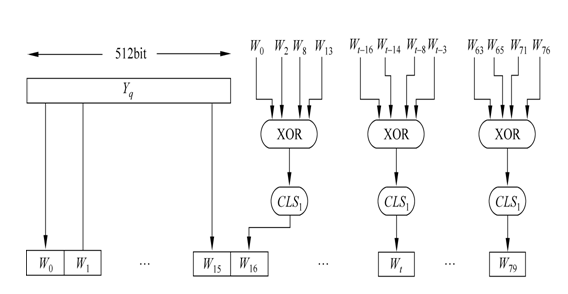
下面说明如何由输入分组(512比特长)导出Wt(32比特长):

即:
3. SHA1 VS MD5
看完了SHA1,就一句话,跟MD5真TM的像啊。。。
那么,就让我们来对比一下:
- 抗穷搜索攻击的强度:
由于SHA和MD5的消息摘要长度分别为160和128,所以用穷搜索攻击寻找具有给定消息摘要的消息分别需做O(2^160)和O(2^128)次运算,而用穷搜索攻击找出具有相同消息摘要的两个不同消息分别需做O(2^80)和O(2^64)次运算。因此SHA抗击穷搜索攻击的强度高于MD5抗击穷搜索攻击的强度。
- 抗击密码分析攻击的强度:
由于SHA的设计准则未被公开,所以它抗击密码分析攻击的强度较难判断,似乎高于MD5的强度
- 速度:
由于两个算法的主要运算都是模232加法,因此都易于在32位结构上实现。但比较起来,SHA的迭代步数(80步)多于MD5的迭代步数(64步),所用的缓冲区(160比特)大于MD5使用的缓冲区(128比特),因此在相同硬件上实现时,SHA的速度要比MD5的速度慢。
- 简洁与紧致性:
两个算法描述起来都较为简单,实现起来也较为简单,都不需要大的程序和代换表。
- 数据的存储方式:
MD5使用little-endian方式,SHA使用big-endian方式。两种方式相比看不出哪个更具优势,之所以使用两种不同的存储方式是因为设计者最初实现各自的算法时,使用的机器的存储方式不同。
0x03 超进化!Hash+MAC=HMAC
不知道有没有注意到一个问题,就是杂凑算法只是对明文进行了一个压缩,产生了一个数据摘要,没有引入密钥的概念,并没有体现认证性,只保证了数据的完整性。
这是,HMAC应运而生。
数据认证算法是传统上构造MAC最为普遍使用的方法,即基于分组密码的构造方法。但近年来研究构造MAC的兴趣已转移到基于密码散列函数的构造方法(HMAC)。这是因为:密码散列函数(如MD5、SHA)的软件实现快于分组密码(如DES)的软件实现;密码散列函数的库代码来源广泛; 密码散列函数没有出口限制,而分组密码有出口限制。
散列函数并不是为用于MAC而设计的,由于散列函数不使用密钥,因此不能直接用于MAC。
目前已提出了很多将散列函数用于构造MAC的方法,其中HMAC就是其中之一,已作为RFC2104被公布,并在IPSec和其他网络协议(如SSL)中得以应用。
RFC2104列举了HMAC的设计目标:
- 可不经修改而使用现有的散列函数,特别是那些易于软件实现的、源代码可方便获取且免费使用的散列函数。
- 其中镶嵌的散列函数可易于替换为更快或更安全的散列函数。
- 保持镶嵌的散列函数的最初性能,不因用于HMAC而使其性能降低。
- 以简单方式使用和处理密钥。
- 在对镶嵌的散列函数合理假设的基础上,易于分析HMAC用于认证时的密码强度。
其中前两个目标是HMAC被公众普遍接受的主要原因,这两个目标是将散列函数当作一个黑盒使用,这种方式有两个优点:
- 散列函数的实现可作为实现HMAC的一个模块,这样一来,HMAC代码中很大一块就可事先准备好,无需修改就可使用;
- 如果HMAC要求使用更快或更安全的散列函数,则只需用新模块代替旧模块,例如用实现SHA的模块代替MD5的模块。
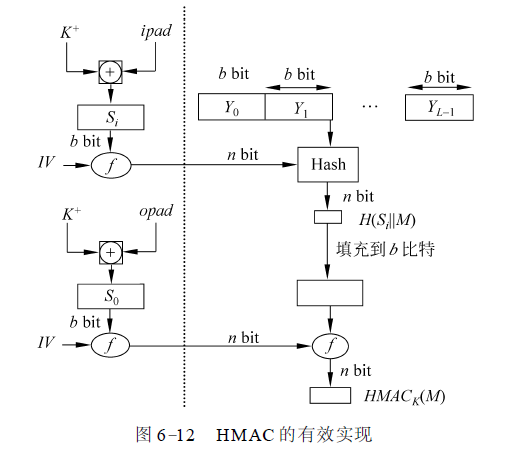
HMAC算法实现
HMAC算法的运行总框图:
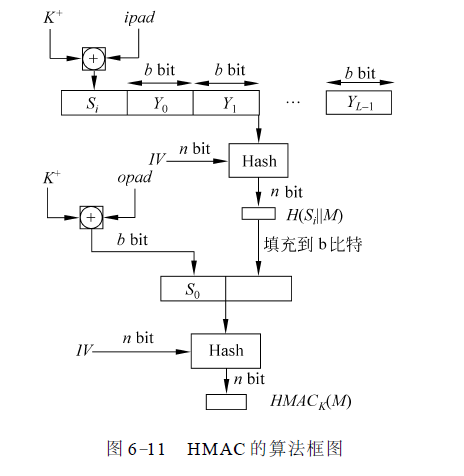
总体解释:上图是HMAC算法的运行框图,其中H为嵌入的散列函数(如MD5、SHA),M为HMAC的输入消息(包括散列函数所要求的填充位),Yi(0≤i≤L-1)是M的第i个分组,L是M的分组数,b是一个分组中的比特数,n为由嵌入的散列函数所产生的杂凑值的长度,K为密钥,如果密钥长度大于b,则将密钥输入到散列函数中产生一个n比特长的密钥,K+是左边经填充0后的K,K+的长度为b比特,ipad为b/8个00110110,opad为b/8个01011010。
HMAC算法流程
- K的左边填充0以产生一个b比特长的K+ (例如K的长为160比特,b=512,则需填充44个零字节0x00)。
- K+与ipad 逐比特异或以产生b比特的分组Si。
- 将M链接到Si后。
- 将H作用于步骤3产生的数据流。
- K+与opad逐比特异或,以产生b比特长的分组S0。
- 将步骤4得到的杂凑值链接在S0后。
- 将H作用于步骤⑥产生的数据流并输出最终结果。
注意,K+与ipad逐比特异或以及K+与opad逐比特异或的结果是将K中的一半比特取反,但两次取反的比特的位置不同。而Si和S0通过散列函数中压缩函数的处理,则相当于以伪随机方式从K产生两个密钥。
HMAC流程简化

HMAC算法安全性
基于散列函数构造的MAC的安全性取决于镶嵌的散列函数的安全性,而HMAC最吸引人的地方是它的设计者已经证明了算法的强度和嵌入的散列函数的强度之间的确切关系,证明了对HMAC的攻击等价于对内嵌散列函数的下述两种攻击之一:
- 攻击者能够计算压缩函数的一个输出,即使IV是随机的和秘密的。
- 攻击者能够找出散列函数的碰撞,即使IV是随机的和秘密的。
在第一种攻击中,可将压缩函数视为与散列函数等价,而散列函数的n比特长IV可视为HMAC的密钥。对这一散列函数的攻击可通过对密钥的穷搜索来进行,也可通过第Ⅱ类生日攻击来实施,通过对密钥的穷搜索攻击的复杂度为O(2^n),通过第Ⅱ类生日攻击又可归结为上述第二种攻击。
第二种攻击指攻击者寻找具有相同杂凑值的两个消息,因此就是第Ⅱ类生日攻击。对杂凑值长度为n的散列函数来说,攻击的复杂度为O(2^(n/2))。因此第二种攻击对MD5的攻击复杂度为O(2^64),就现在的技术来说,这种攻击是可行的。但这是否意味着MD5不适合用于HMAC?
回答是否定的,原因如下:攻击者在攻击MD5时,可选择任何消息集合后脱线寻找碰撞。由于攻击者知道杂凑算法和默认的IV,因此能为自己产生的每个消息求出杂凑值。然而,在攻击HMAC时,由于攻击者不知道密钥K,从而不能脱线产生消息和认证码对。所以攻击者必须得到HMAC在同一密钥下产生的一系列消息,并对得到的消息序列进行攻击。对长128比特的杂凑值来说,需要得到用同一密钥产生的2^64个分组(2^73比特)。在1Gbit/s的链路上,需250000年,因此MD5完全适合于HMAC,而且就速度而言,MD5要快于SHA作为内嵌散列函数的HMAC。
消息认证机制就到这了。。。
密码的话,写到这就算告一段落了,写的密码都是一些最基础的东西,但基础最重要嘛。。。感觉密码还是蛮好玩的,但自己还是没入门,所以以后也会加强自己在密码上的学习,有什么在密码上的新发现的话,也会及时更新blog的。。。
接下来的话,就要转入总结编写各种exp的计划了,希望能够让自己的pwn更有体系,更加自动化,更上一层楼,就这样。。。。
