密码系列6-分组密码的尾声之IDEA和AES
0x00 口胡
对于IDEA的介绍只是简单带过,重点介绍AES
0x01 IDEA
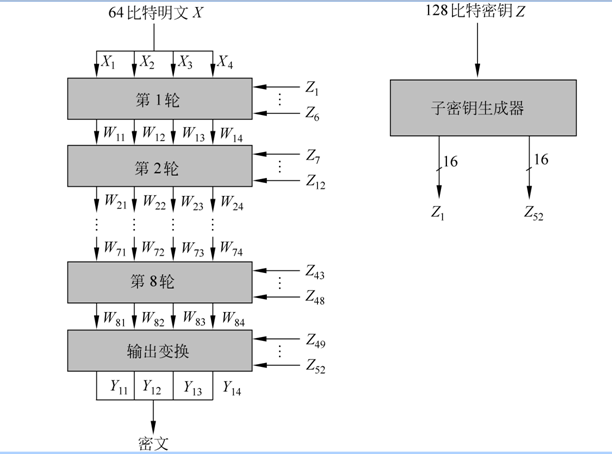
- IDEA分组长度64比特。
- 密钥是128比特。
- 加密过程是8轮。
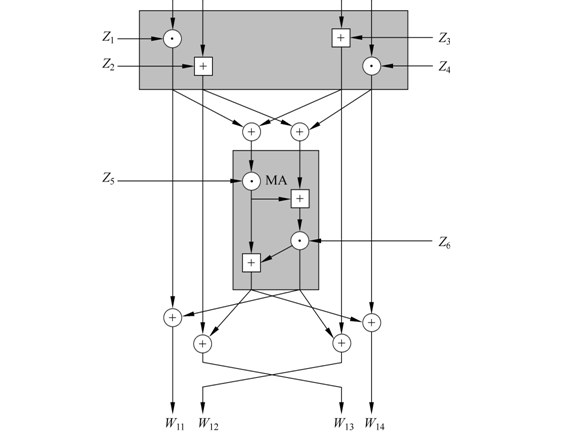
具体加密过程如下图:

0x02 AES
1997年4月15日,美国ANSI发起征集AES(advanced encryption standard)的活动。此次活动的目的是确定一个非保密的、可以公开技术细节的、全球免费使用的分组密码算法,以作为新的数据加密标准。1997年9月12日,美国联邦登记处公布了正式征集AES候选算法的通告。对AES的基本要求是: 比三重DES快、至少与三重DES一样安全。1998年8月12日,在首届AES候选会议上公布了AES的15个候选算法,任由全世界各机构和个人攻击和评论,这15个候选算法是CAST256、CRYPTON、E2、DEAL、FROG、SAFER+、RC6、MAGENTA、LOKI97、SERPENT、MARS、Rijndael、DFC、Twofish、HPC。2000年10月2日,NIST宣布Rijndael作为新的AES。至此,经过3年多的讨论,Rijndael终于脱颖而出。
AES流程
关于AES的数学基础和设计思想,我们在讲流程的时候具体用到时再来讨论,先来谈论具体的流程,看看AES加密算法到底是什么样子的。
Rijndael 是一个迭代型分组密码, 其分组长度和密钥长度都可变, 各自可以独立地指定为128 比特、192 比特、256 比特。
1.状态、种子密钥和轮数
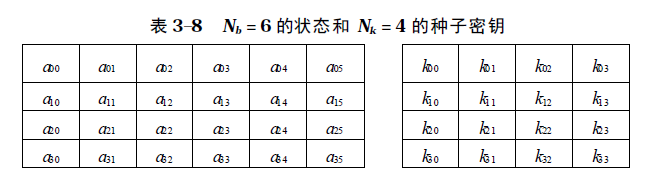
类似于明文分组和密文分组, 算法的中间结果也须分组, 称算法中间结果的分组为状态, 所有的操作都在状态上进行。状态可以用以字节为元素的矩阵阵列表示, 该阵列有4行, 列数记为Nb , Nb 等于分组长度除以32。
种子密钥类似地用一个以字节为元素的矩阵阵列表示, 该阵列有4 行, 列数记为Nk , Nk等于分组长度除以32。表3-8 是Nb = 6 的状态和Nk = 4 的种子密钥的矩阵阵列表示。
有时可将这些分组当作一维数组, 其每一元素是上述阵列表示中的4 字节元素构成的列向量, 数组长度可为4、6、8 , 数组元素下标的范围分别是0~3、0~5 和0~7。4 字节元素构成的列向量有时也称为字。
算法的输入和输出被看成是由8 比特字节构成的一维数组, 其元素下标的范围是0~(4 Nb - 1 ) , 因此输入和输出以字节为单位的分组长度分别是16、24 和32 , 其元素下标的范围分别是0~15、0~23 和0~31。输入的种子密钥也看成是由8 比特字节构成的一维数组, 其元素下标的范围是0~( 4 Nk - 1) , 因此种子密钥以字节为单位的分组长度也分别是16、24 和32 , 其元素下标的范围分别是0~15、0~23 和0~31。算法的输入( 包括最初的明文输入和中间过程的轮输入) 以字节为单位按a00 a10 a20 a30 a01 a11 a21 a31 ⋯ 的顺序放置到状态阵列中。同理, 种子密钥以字节为单位按k00 k1 0 k20 k30 k01 k1 1 k21 k31 ⋯ 的顺序放置到种子密钥阵列中。而输出( 包括中间过程的轮输出和最后的密文输出) 也是以字节为单位按相同的顺序从状态阵列中取出。若输入(或输出) 分组中第n 个元素对应于状态阵列的第( i, j ) 位置上的元素, 则n 和( i, j ) 有以下关系:i = n mod 4; j = n/ 4的结果下取整 ; n = i + 4 j迭代的轮数记为Nr , Nr与Nb 和Nk 有关, 表3 -9 给出了Nr 与Nb和Nk 的关系。
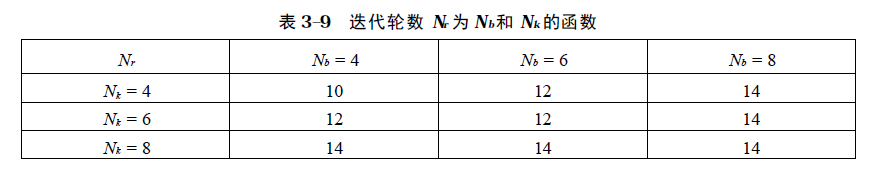
2. 轮函数
Rijndael 的轮函数由4 个不同的计算部件组成, 分别是: 字节代换(ByteSub )、行移位( ShiftRow) 、列混合(MixColumn) 、密钥加( AddRoundKey )。伪C代码:1
2
3
4
5
6
7Round (State, RoundKey)
{
ByteSub (State);
ShiftRow (State);
MixColumn (State);
AddRoundKey (State, RoundKey)
}
字节代换(ByteSub)
字节代换是非线形变换,独立地对状态的每个字节进行。代换表(即S-盒)是可逆的,由以下两个变换的合成得到:
- 首先,将字节看作多项式,映射到自己的乘法逆元,‘00’映射到自己。
- 其次,对字节做如下的仿射变换:

达到的效果:
上面提到了将字节看做多项式以及乘法逆元的概念,下面介绍什么是字节多项式及乘法逆元,以及如何求乘法逆元
有限域GF(2^8 )以及多项式的加法、减法、乘法运算:
前面好像提到过有限域的概念。因排版较麻烦,所以直接截图了。。。


对于多项式的乘法,有必要补充一下,就拿‘57’·‘83’=‘C1’这个例子来看,给出如下图来说明计算过程:
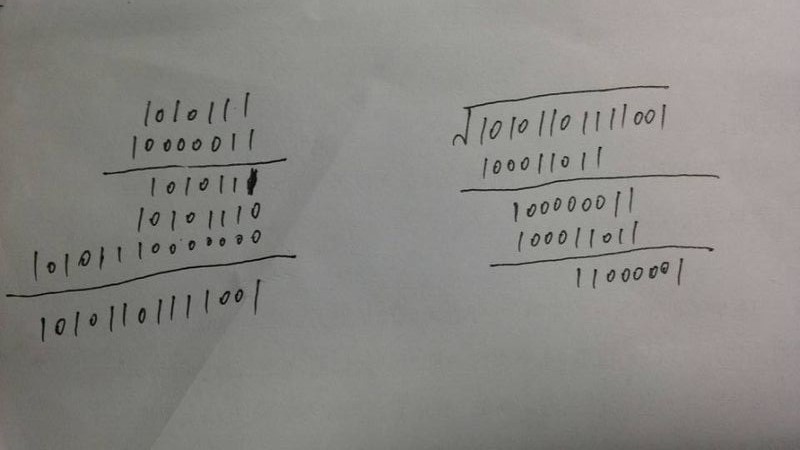
这张图已经很清晰的写出了多项式模乘的运算过程
我们在来看乘法逆元:
对任何次数小于8 的多项式b( x ) , 可用推广的欧几里得算法得b( x) a( x ) + m( x) c( x) = 1即a( x) ·b( x ) = 1 mod m( x) , 因此a( x )是b( x) 的乘法逆元。
对于乘法逆元的求法,就是用大名鼎鼎的扩展欧几里得算法(又称辗转相除法)了,自行google。这里要用到欧几里得算法的逆推过程,给出求逆元的伪代码:
1 | Extended Euclid (d,f) //算法求d关于模f的乘法逆元d-1 ,即 d* d-1 mod f = 1 |
C++代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22inline long long extend_gcd(long long a,long long b,long long &x,long long &y)
{
if(a==0&&b==0)
return -1ll;
if(b==0)
{
x=1ll;
y=0ll;
return a;
}
long long d=extend_gcd(b,a%b,y,x);
y-=a/b*x;
return d;
}
inline long long mod_reverse(long long a,long long n)
{
long long x,y,d=extend_gcd(a,n,x,y);
if(d==1)
return (x%n+n)%n;
else
return -1ll;
}
补充说明:
若ax≡1 mod f, 则称a关于模f的乘法逆元为x。也可表示为ax≡1(mod f)。当a与f互素时,a关于模f的乘法逆元有唯一解。如果不互素,则无解。如果f为素数,则从1到f-1的任意数都与f互素,即在1到f-1之间都恰好有一个关于模f的乘法逆元。
对于上面的C++代码,当d==1时,说明二者是互素的,即二者的最大公约数是1,扩展的欧几里得算法实际上是通过辗转相除法来求得两个数的最大公约数,只不过上面不论是伪代码还是C++代码,都是在将这个辗转相相除的中间过程记录下来,以便后面反向迭代求逆元时用。给出一个具体的例子,比如我们要求5关于模14的乘法逆元。首先我们通过辗转相除法来做,14/5=2余4,5/4=1余1,4/1=4余0,到这里,我们可以确定gcd(14,5)=gcd(4,1)=1,即14和5互素,则5关于模14的乘法逆元有唯一解,那么如何求乘法逆元呢,答案就是将辗转相除的过程反向迭代回去,上面代码也是通过递归体现一个反向迭代的过程。有一个定理忘了叫什么了,就是说两个数的最大公约数可以写成两个数的线性表示,比如a,b的最大公约数是c,则c=ma+nb,其中m,n是整数。那么上面14和5的最大公约数是1,所以1=m x 14+n x 5,由乘法逆元的定义可知,n就是5的乘法逆元,n由反向迭代求出。1=5-4 x 1=5-(14-5 x 2) x 1=5 x 3-14;(就这样一直向上迭代,直到迭代到最上层的式子时停止,此时所得到的较小数的系数就是要求的小数关于大数的模逆元)。其实,你仔细总结还会发现,最后得到的两个数的系数是有一定规律的,下面是我根据规律写的python代码,没有递归来的那么直观和便于理解,仅供参考:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49def re_gcd(a,b):
temp_a=a
temp_b=b
result=list()
if(a%b==0):
result.append(1)
result.append(-(int(a/b)-1))
return result
else:
count=0
c=list()
while(a%b!=0):
c.append(int(a/b))
temp=b
b=a%b
a=temp
count+=1
## print(count)
## print(c)
if(count==1):
result.append(1)
result.append(-int(temp_a/temp_b))
return result
elif(count%2!=0):
t=c[count-1]
while(count-1!=0):
s=t
t=t*c[count-2]+1
count-=1
result.append(s)
result.append(-t)
return result
else:
t=c[count-1]
while(count-1!=0):
s=t
t=t*c[count-2]+1
count-=1
result.append(-s)
result.append(t)
return result
a=18
b=12
if(a>=b):
re=re_gcd(a,b)
else:
re=re_gcd(b,a)
print("s=%d\nt=%d\n"%(re[0],re[1]))
强势介绍了一波数学姿势,我们有必要来条分割线压压惊。。。
通过上面的数学姿势,我们已经懂得如何将字节看做多项式,并明白两者是可以相互转化的,并且会求字节的乘法逆元了,那么字节代换对于我们来说已经没有问题了,下面继续来讲流程,为了防止脱节,再将字节代换的流程po一遍
字节代换(ByteSub)
字节代换是非线形变换,独立地对状态的每个字节进行。代换表(即S-盒)是可逆的,由以下两个变换的合成得到:
- 首先,将字节看作多项式,映射到自己的乘法逆元,‘00’映射到自己。
- 其次,对字节做如下的仿射变换:
行移位(Shift Row)
行移位是将状态阵列的各行进行循环移位, 不同状态行的位移量不同。第0 行不移动, 第1 行循环左移C1 个字节, 第2 行循环左移C2 个字节, 第3 行循环左移C3 个字节。位移量C1 、C2 、C3 的取值与Nb 有关, 由下表给出。
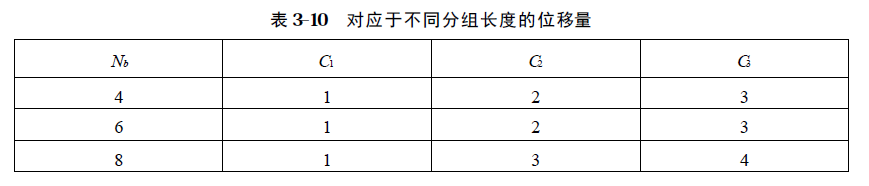
按指定的位移量对状态的行进行的行移位运算记为ShiftRow ( State ),行移位示意图:
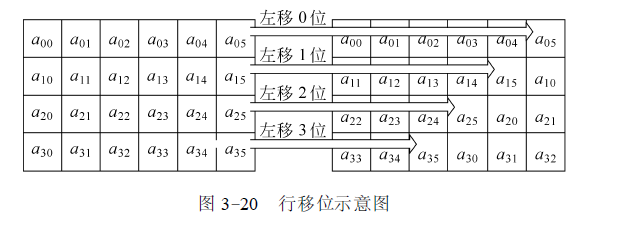
Shift Row 的逆变换是对状态阵列的后3 列分别以位移量Nb - C1 、Nb - C2 、Nb - C3进行循环移位, 使得第i 行第j 列的字节移位到( j + Nb - Ci ) mod Nb 。这里注意一下,逆变换是对状态阵列的后3 列进行的变换的,这样做的确可以变换为原来的状态。可能有同学会问,为甚不能直接对行进行逆变换,个人觉着没什么不妥,可能是我哪考虑不周全,但是这样做是经过很多砖家鉴定的,所以说对状态阵列的后3 列进行循环变换是不会错的。
列混合(MixColumn)
在列混合变换中, 将状态阵列的每个列视为GF(2^8 ) 上的多项式, 再与一个固定的多项式c( x )进行模x^4 + 1 乘法。当然要求c( x) 是模x^4 + 1 可逆的多项式, 否则列混合变换就是不可逆的, 因而会使不同的输入分组对应的输出分组可能相同。
这里有必要说明下,如何将每个列视为GF(2^8 )上的多项式。还记得我们上面说的对于单个字节,可以将单个字节视为多项式,这里,我们知道,每个列是4字节,这里引入系数在GF(2^8 )上的多项式的概念:


这里对于系数多项式,对于系数多项式的模乘运算,要说这本书真是写的烂,这些具体的计算细节啊原则啊什么的从来都不写出来,搞得我云里雾里的。。。从网上无意间发现了下面东西-密码算法详解——AES其中有讲解系数多项式模乘运算的细节,直接截图:


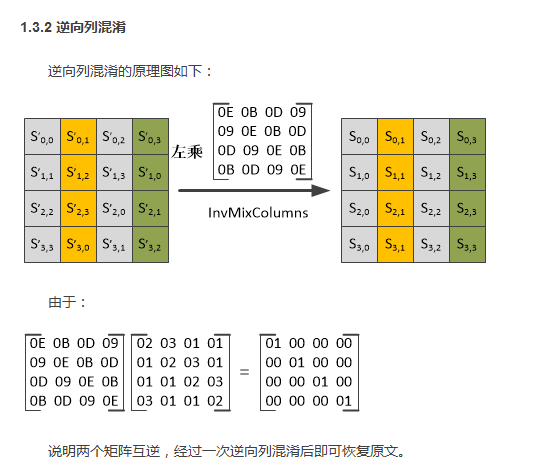
这样,对于系数多项式的模乘我们就知道具体是如何计算了
修改于 0x10.0x01.0x08
今天朋友看我blog,估计也就我这俩朋友看了,呵呵。。。
经朋友指点,我这里写的是不完整的,我忽略了书的一个重要内容,导致我的理解错了,不过书的排版真是有问题。
这里和朋友讨论后,将多项式的乘法在这里从头到尾的捋一遍。
怎么说呢,首先是对于单个字节,比如十进制数87,表示为二进制形式为1010111,它对应的多项式为x^6 + x^4 + x^2 + x + 1,相应的,再来个十进制数131,它对应的多项式为x^7 + x + 1,好了,对于单个字节对应的多项式的模乘应该怎么做呢,这里模是事先规定的,如x^8 + x^4 + x^3 + x + 1,下面直接给出计算方法,就是表示为二进制后再进行乘,然后用二进制结果去除模的二进制表示,得到的余数就是最后结果,上图:
上面是单个字节对应的多项式的模乘运算,那么系数多项式呢?
由于系数多项式是由4个字节构成的,形式为a3x^3+a2x^2+a1^x+a0,这里每个项的系数(a3,a2,a1,a0)各自对应一个字节,一个字节有8位,也就是说系数的取值范围是[0,255],介绍完了系数多项式的格式,我们来看系数多项式是如何进行模乘运算的。
给定两个系数多项式:a(x)= a3x^3+a2x^2+a1x+a0,b(x)= b3x^3+b2x^2+b1x+b0,我们定义系数多项式的模乘运算为c(x)= a(x)b(x)=c3x^3+c2x^2+c1^x+c0 (mod x^4+1),这里模x^4+1是为了使得次数小于4 的多项式的乘积仍然是一个次数小于4 的多项式,这时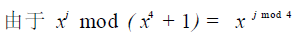 ,所以我们将上面的运算表示为
,所以我们将上面的运算表示为
这就是模乘运算,根据这个定义我们可以得到c0=a0 x b0+a3 x b1+a2 x b2+a1 x b3(注意这里的+都是模2加),但这里必须要强调的一点就是,一定要注意的一点就是对于系数相乘时采取时所采取的运算规则,即a0 x b0怎么算?
由于a0和b0的取值范围都是[0,255],但他们两的乘法运算并不采用字节多项式采用的模乘运算法则,他们采用另一种运算法则,我们称之为x乘法,给出x乘法的运算法则:

比如当a0=02,b0=c9时,x乘法对应的运算为:
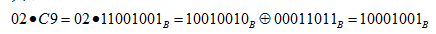
再来看个稍微复杂点的情况,a0=03,b0=6e时,x乘法对应的运算为:
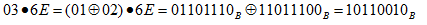
也就是说把03拆成了01 + 02(注意这里的加为异或运算,即模2加运算),然后分别用01乘6e,02乘6e(这里的乘都是x乘法),对于01和02的x乘法我们已经会了,最后结果就是将这两个的结果加起来(注意这里的加为异或运算,即模2加运算),就是这样。
再来看个一般的情况,比如a0=57(16进制),b0=13(16进制),这里我们可以这样算,首先我们选取两数中较小的数(0x13),将他像上面的0x3一样,拆成几个2的指数倍的数异或的形式,因为0x13=0x1 xor 0x2 xor 0x10(0x10=0x2^4),然后将拆开的数分别于另一个数(0x57)进行x乘法运算,在此例中,0x1和0x2与0x57的x乘法我们已经会了,那么0x10与0x57的x乘法怎么算呢?
这样算:由于0x10是0x2^4,即0x10 x 0x57(这里的乘法是x乘法)=(0x2 x (0x2 x (0x2 x (0x2 x 0x57)))),也就是说相当于向左移4位,根据x乘法的运算规则,在每一次和0x2相乘时都采用x乘法运算法则,描述为0x57 x 0x2进行x乘法,结果再与2进行x乘法,结果再与2进行x乘法,结果再与2进行x乘法,然后就得到了最终结果了,恩,就是这样。对于0x57和0x13的x乘法,给出下图:
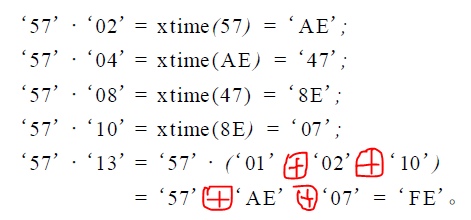
这样,对于字节多项式的模乘运算以及系数多项式的模乘多项式我们就都搞清楚了,还是跟朋友讨论能得到姿势啊。。。
对于上面提到的c(x):


对状态State 的所有列所做的列混合运算记为MixColumn( State ),列混合整体效果图:
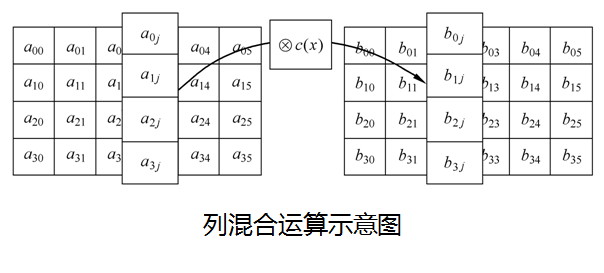
对于逆运算:

密钥加( AddRoundKey)
密钥加是将轮密钥简单地与状态进行逐比特异或。轮密钥由种子密钥通过密钥编排算法得到, 轮密钥长度等于分组长度Nb。状态State 与轮密钥RoundKey 的密钥加运算表示为AddRoundKey ( State, RoundKey),密钥加的整体效果图:
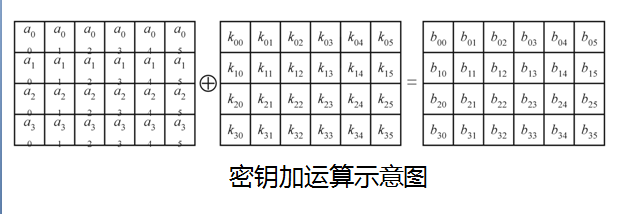
对于逆运算,密钥加运算的逆运算是其自身。
综上所述, 组成Rijndael 轮函数的计算部件简捷快速, 功能互补。轮函数的伪C 代码如下:1
2
3
4
5
6
7Round (State , RoundKey)
{
ByteSub (State ) ;
ShiftRow (State ) ;
MixColumn (Sta te) ;
AddRoundKey (State , RoundKey)
}
结尾轮的轮函数与前面各轮不同, 将MixColumn 这一步去掉, 其伪C 代码如下:1
2
3
4
5
6FinalRound ( State , RoundKey)
{
ByteSub (State ) ;
ShiftRow (State ) ;
AddRoundKey (State , RoundKey)
}
在以上伪C 代码记法中, State、RoundKey 可用指针类型, 函数Round、FinalRound、ByteSub、Shift Row、MixColumn、AddRoundKey 都在指针Sta te、RoundKey 所指向的阵列上进行运算。
3. 密钥编排
密钥编排指从种子密钥得到轮密钥的过程, 它由密钥扩展和轮密钥选取两部分组成。其基本原则如下:
- 轮密钥的比特数等于分组长度乘以轮数加1;
- 种子密钥被扩展成为扩展密钥;
- 轮密钥从扩展密钥中取, 其中第1 轮轮密钥取扩展密钥的前Nb 个字, 第2 轮轮密钥取接下来的Nb 个字, 如此下去。
排版问题(md用的不熟),直接截图:





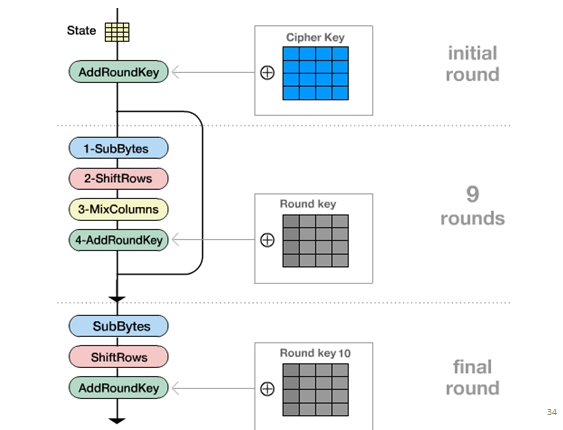
4. 加密算法
加密算法为顺序完成以下操作: 初始的密钥加; ( Nr - 1) 轮迭代;一个结尾轮。即1
2
3
4
5
6
7Rijndael (State , Ciphe rKey)
{
KeyExpansion (Ciphe rKey , ExpandedKey) ;
AddRoundKey (State , ExpandedKey) ;
for ( i = 1; i < Nr ; i + + ) Round (State , ExpandedKey + Nb * i) ;
FinalRound (State, ExpandedKey + Nb * Nr )
}
其中CipherKey 是种子密钥, ExpandedKey 是扩展密钥。密钥扩展可以事先进行( 预计算) , 且Rijndael 密码的加密算法可以用这一扩展密钥来描述, 即1
2
3
4
5
6Rijndael (State , ExpandedKey)
{
AddRoundKey (State , ExpandedKey) ;
for ( i = 1; i < Nr ; i + + ) Round (State , ExpandedKey + Nb * i) ;
FinalRound (State, ExpandedKey + Nb * Nr )
}
5. 加解密的相近程度及解密算法
首先给出几个引理。
引理1 设字节代换(ByteSu b) 、行移位( Shif tRow ) 的逆变换分别为InvByteSub、InvShift Row。则组合部件“ ByteSub → Shif tRow ”的逆变换为“ InvByteSub →InvShift Row”。
证明: 组合部件“ ByteSu b → Shift Row”的逆变换原本为“ InvShif tRow →InvByteSub”。由于字节代换(ByteSub) 是对每个字节进行相同的变换, 故“InvShiftRow”与“InvByteSub”两个计算部件可以交换顺序。( 证毕)
引理2 设列混合(MixColumn ) 的逆变换为InvMixColumn。则列混合部件与密钥加部件( AddRoundKey )的组合部件“MixColumn→AddRoundKey (· , Key )”的逆变换为“InvMixColumn→AddRoundKey (· , InvKey)”。其中密钥InvKey 与Key 的关系为: InvKey = InvMixColumn ( Key) 。证明: 组合部件“MixColumn → AddRoundKey ( · , Key )” 的逆变换原本为“AddRoundKey (· , Key ) →InvMixColumn”, 由于列混合(MixColumn) 实际上是线性空间GF(28 )4 上的可逆线性变换, 因此“AddRoundKey (·, Key) → InvMixColumn”=“InvMixColumn → AddRoundKey (·, InvMixColumn ( Key) )” ( 证毕)
引理3 将某一轮的后两个计算部件和下一轮的前两个计算部件组成组合部件,
该组合部件的程序为1
2
3
4MixColumn (State ) ;
AddRoundKey (Sta te, Key( i) ) ;
ByteSub (State) ;
Shif tRow (State)
则该组合部件的逆变换程序为1
2
3
4InvByteSub (State ) ;
InvShiftRow (State ) ;
InvMixColumn (State) ;
AddRoundKey (Sta te, InvMixColumn (Key( i) ) )
证明: 这是引理3 -1 和引理3 -2 的直接推论。
Rijndael 密码的解密算法为顺序完成以下操作: 初始的密钥加; ( Nr - 1 )
轮迭代; 一个结尾轮。其中解密算法的轮函数为1
2
3
4
5
6
7InvRound (Sta te, RoundKey)
{
InvByteSub ( State ) ;
InvShif tRow ( State ) ;
InvMixColumn (State ) ;
AddRoundKey (State , RoundKey)
}
解密算法的结尾轮为1
2
3
4
5
6InvFinalRound (State, RoundKey)
{
InvByteSub ( State ) ;
InvShif tRow ( State ) ;
AddRoundKey (State , RoundKey)
}
设加密算法的初始密钥加、第1 轮、第2 轮、⋯、第Nr 轮的子密钥依次为
k(0 ) , k( 1) , k(2 ) , ⋯ , k( Nr - 1) , k( Nr )
则解密算法的初始密钥加、第1 轮、第2 轮、⋯、第Nr 轮的子密钥依次为
k( Nr ) , InvMixColumn ( k( Nr - 1) ) , InvMixColumn ( k( Nr - 2 ) ) , ⋯ ,
InvMixColumn ( k(1 ) ) , k(0 )。
证明: 这是上述3 个引理的直接推论。
综上所述, Rijndael 密码的解密算法与加密算法的计算网络相同, 只是将各计算部件换为对应的逆部件。这样,在具体的工业实现中就不用重新做一块板子了,节约成本。
终于写完了分组密码,本来信心满满的开始写这个系列,写到这里突然有点恶心,感觉写着写着就变味了,写成了傻逼教科书式的blog,但没办法,我对于密码的理解一点也不深,抓不住重点,觉着都挺重要的,就都写上了。下面就到了公钥密码体制了,希望能写的有趣一点,自己也能写的开心一点。
