密码初探-玩bin的人怎么能不懂密码呢
0x01 前情提要
本文不像前几篇一样,不会这么注重框架性和体系性。本文以及相关的后续blog的目的在于介绍各种你所耳熟能详的几种密码的具体姿势。鉴于朋友说前几篇blog太长,所以这里打算把密码写成一个系列,并且在排版上也会上点心。。。
0x02 正片
说到密码,每个人都有每个人的第一印象。其实在很久以前,人们就有了对信息加密的意识,这里,古典密码不得不提。
古典密码
古典密码的加密体现的是一种代换的思想。包括单表代换密码和多表代换密码,单表代换如经典的恺撒密码,移位变换,仿射变换等。这里简单说一下,恺撒密码,加密时每个字母后移3位,然后mod26,解密时,每个字母前移3位,然后mod26,其中3就是加解密所用的密钥。移位变换是移k位,仿射变换(该图来自百度百科):

上图中的k3是k1的逆元,关于逆元的概念,下面会谈到
对于多表代换密码,自己懒得写,直接把书上的东西po出来(渣像素,见谅):
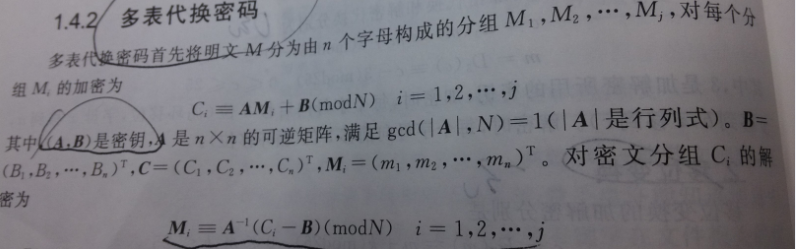
关于古典密码的介绍就到这,古典密码的代换思想在现代密码中有很多体现。现在我们来看现代密码
现代密码
现代密码系统可以用一个看一眼就懂的五元组表示:
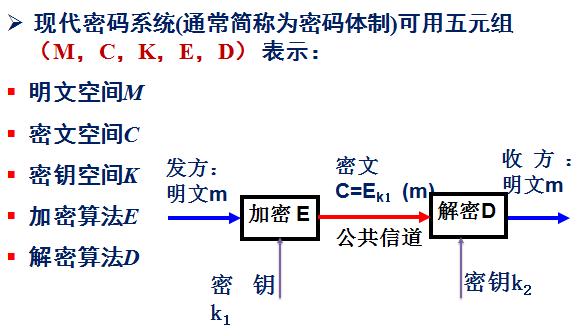
这里主要从密码的体制上来展开对密码的讨论
密码体制从原理上可以分为两大类,即单钥体制和双钥体制
单钥体制又称对称密码体制,就是加密密钥和解密密钥相同。对称密码体制按照对明文加密方式的不同,分为序列密码和分组密码。序列密码(stream cipher):又称流密码。序列密码每次通过输出密钥流序列加密(通常是模2加,即异或运算)一位或一字节的明文。如A5、RC4等。分组密码(block cipher):将明文分成固定长度的组,用同一密钥和算法对每一块加密,输出也是固定长度的密文。如DES、IDEA、AES等
双钥体制又称非对称密码体制,就是加密密钥和解密密钥不相同,从一个很难推出另一个,又称公开密钥体制。
说了要写一个系列的,所以这篇就主要讲流密码(序列密码)了
0x03 本篇重点——序列密码
序列密码的基本思想是采用一个短的密钥来控制某种算法产生出长的密钥序列,供加、解密使用,利用密钥k产生一个伪随机序列密钥流z=z0z1…,并使用如下规则对明文串x=x0x1x2…加密:y=y0y1y2…= (x0+z0) (x1+z1) …
过程如图所示:
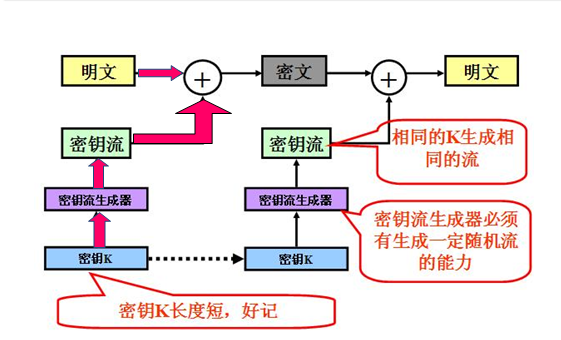
根据加密器中记忆元件的存储状态σi 是否依赖于输入的明文字符, 流密码可进一步分成同步和自同步两种。σi 独立于明文字符的叫做同步流密码, 否则叫做自同步流密码。由于自同步流密码的密钥流的产生与明文有关, 因而较难从理论上进行分析,目前大多数研究成果都是关于同步流密码的,因此同步流密码也是我们讨论的重点。
可见同步流密码的关键是密钥流产生器。目前最为流行和实用的密钥流产生器是通过线性反馈移位寄存器来实现密钥的产生。移位寄存器是流密码产生密钥流的一个主要组成部分。GF(2 )上一个n 级反馈移位
寄存器由n 个二元存储器与一个反馈函数f ( a1 , a2 , ⋯ , an )组成,如图:
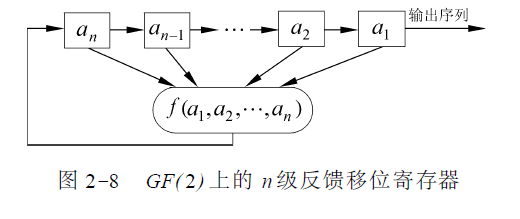
每一存储器称为移位寄存器的一级, 在任一时刻, 这些级的内容构成该反馈移位寄存器的状态, 每一状态对应于GF( 2)上的一个n 维向量, 共有2^n 种可能的状态。每一时刻的状态可用n 长序列a1 , a2 , ⋯ , an或n 维向量( a1 , a2 , ⋯ , an )表示, 其中ai 是第i 级存储器的内容。初始状态由用户确定, 当第i 个移位时钟脉冲到来时, 每一级存储器ai 都将其内容向下一级ai - 1 传递, 并根据寄存器此时的状态a1 , a2 , ⋯ ,an 计算f ( a1 , a2 , ⋯ , an ) , 作为下一时刻的an 。反馈函数f ( a1 , a2 , ⋯ , an )是n 元布尔函数, 即n 个变元a1 , a2 , ⋯ , an 可以独立地取0 和1 这两个可能的值, 函数中的运算有逻辑与、逻辑或、逻辑补等运算, 最后的函数值也为0 或1。
其实上面的过程可以形象的想象成鸡下蛋的过程,鸡肚子中存储的蛋的数量是有限的。首先,用户,没错,就是你,你让鸡怀上了鸡所能承受的最多的蛋,然后鸡开始下蛋,并且鸡每下一个蛋(认为产生了一个密钥位),你或者其他什么东西又会立马使它怀上一个蛋,且这个蛋的产生与这只鸡还没生蛋前的所有肚子里的蛋有关系,至于是什么关系,这是用户,没错,还是你,可以去定义的,这样,鸡就会一直下蛋,相当于一个密钥流产生器。
如果移位寄存器的反馈函数f ( a1 , a2 , ⋯ , an ) 是a1 , a2 , ⋯ , an 的线性函数, 则称之为线性反馈移位寄存器LFSR( linear feedback shiftregister ) 。这里我们需要注意的是,由于线性反馈寄存器都是按位来计算的,所以这里的线性函数中各个项之间的运算基本上都是模2加,即异或操作。此时f 可写为f ( a1 , a2 , ⋯ , an ) = cn a1 + cn - 1 a2 + ⋯ + c1 an其中常数ci = 0 或1 ,+是模2 加法。ci = 0 或1 可用实际电路的开关的断开和闭合来实现,如图:
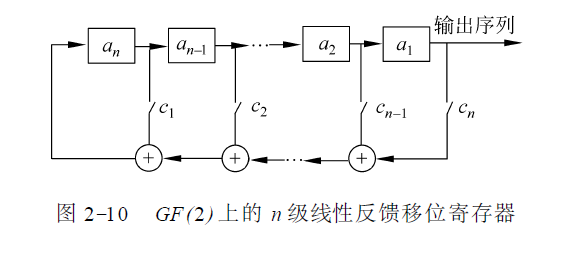
则,输出序列{ at }满足:an + t = cn at + cn - 1 at+ 1 + ⋯ + c1 an + t - 1,线性反馈移位寄存器因其实现简单、速度快、有较为成熟的理论等优点而成为构造密钥流生成器的最重要的部件之一。在线性反馈移位寄存器中总是假定c1 , c2 , ⋯ , cn 中至少有一个不为0 , 否则f ( a1 ,a2 , ⋯ , an )≡0 , 这样的话, 在n 个脉冲后状态必然是00⋯0 , 且这个状态必将一直持续下去。若只有一个系数不为0 , 设仅有cj 不为0 , 实际上是一种延迟装置。一般对于n 级线性反馈移位寄存器, 总是假定cn = 1。线性反馈移位寄存器输出序列的性质完全由其反馈函数决定。n 级线性反馈移位寄存器最多有2^n 个不同的状态。若其初始状态为0 , 则其状态恒为0。若其初始状态非0 ,则其后继状态不会为0。因此n 级线性反馈移位寄存器的状态周期小于等于2^n - 1。其输出序列的周期与状态周期相等, 也小于等于2^n - 1。只要选择合适的反馈函数便可使序列的周期达到最大值2^n - 1 , 周期达到最大值的序列称为m 序列。
流密码的安全性取决于密钥流的安全性, 要求密钥流序列有好的随机性, 以使密码分析者对它无法预测。也就是说, 即使截获其中一段, 也无法推测后面是什么。如果密钥流是周期的, 要完全做到随机性是困难的。严格地说, 这样的序列不可能做随机, 只能要求截获比周期短的一段密钥流时不会泄露更多信息, 这样的序列称为伪随序列。为讨论m 序列的随机性, 先要讨论随机序列的一般特性。
前方数学高能,先来个分割线压压惊。
游程:设{ ai } = ( a1 a2 a3 ⋯) 为0、1 序列, 例如00110111 , 其前两个数字是00 , 称为0 的2 游程; 接着是11 , 是1 的2 游程;再下来是0 的1 游程和1 的3 游程。
自相关函数:

定义中的和式表示序列{ ai } 与{ ai + τ} ( 序列{ ai }向后平移τ位得到)在一个周期内对应位相同的位数与对应位不同的位数之差。当τ= 0时, R(τ) = 1; 当τ≠0 时, 称R(τ) 为异相自相关函数。这个自相关函数是为了比较序列在经过移位操作后与原序列的相似程度,因为从这个式子的意义出发,ai在移动τ位后,会处在ai+τ的位置上,此时ai+τ位置上的值是ai,而原来ai+τ的位置上是ai+τ,所以这个式子的每一项算的就是移位后,相同位置上的数字是否相同,如果相同,则这一项为1,不同为-1,然后逐项的结果相加。这个自相关函数可以衡量出移位操作前后,序列的相似程度,这样是为了防止通过移位找到序列的一些规律而造成序列的随机性遭到破坏。
对于序列的随机性,Golomb(我也不知道咋读)这个人提出了他的看法,他认为,一个良好的伪随机序列应当满足如下三个随机性公设(将用到我们上面介绍的游程以及自相关函数的概念):

公设①说明{ ai }中0 与1 出现的概率基本上相同, ②说明0 与1 在序列中每一位置上出现的概率相同; ③意味着通过对序列与其平移后的序列做比较, 不能给出其他任何信息。从密码系统的角度看, 一个伪随机序列还应满足下面的条件:
① { ai }的周期相当大。
② { ai }的确定在计算上是容易的。
③ 由密文及相应的明文的部分信息, 不能确定整个{ ai }。
而我们研究的m序列就满足上面的3个随机性公设,因为,定理告诉我们,它是满足的:
定理:GF(2 )上的n 长m 序列{ ai }具有如下性质:

我们来看定理的证明:




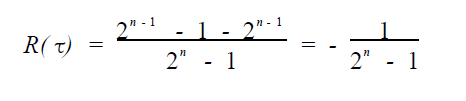
可以看出,m序列很好的满足了3个随机性公设,也就是说它具有良好的伪随机性,也就是说这个序列可以用来做密钥流,所以当我们设计密钥流产生器时,我们可以使密钥的生成去尽量接近m序列。针对密钥流的构造,我们给定初始状态,以及状态转换函数应使接下来的状态尽量具有良好的伪随机性,这是流密码密钥设计的一个原则。
流密码的破解
有限域GF( 2)上的二元加法流密码是目前最为常用的流密码体制, 设滚动密钥生成器是线性反馈移位寄存器, 产生的密钥是m 序列,它具有良好的伪随机性,那么这时的流密码是不是就不能破解了?并不,我们来看看怎么破,又设Sh 和S h + 1是序列中两个连续的n 长向量,直接上图:





对于流密码的理论部分,就暂时讲到这。。。下篇将流密码在现实中对应的具体算法
下片预告:流密码在现实中的具体应用—A5算法和RC4算法
