if I were a OS--linux0.11源码分析
if I were a OS
0x01 背景介绍
要有份linux0.11的源码在身边
0x02 计算机的启动过程
在我还没有出生之前,即在电脑还没有加载操作系统把自己交给OS之前,我们来看下计算机做了哪些事情,它是如何把自己交给操作系统的。。。
对于计算机的启动过程,我也是看了阮一峰的一篇blog,这里就不copy了,还有langeldep的blog,对很多启动过程中的细节做了补充,这里也不copy了。这里总结下,计算机的启动过程:
首先是计算机加电,CPU马上就从地址FFFF:0000H 处开始执行指令,放在这里的只是一条跳转指令,跳到系统BIOS中真正的启动代码处,bios存放着一些启动程序,bios运行起来后会首先进行硬件自检(POST),硬件自检完成后,bios会将控制权交给下一阶段的启动程序。bios中有一个外部存储设备排序,排在前面的设备就是优先转交控制权的设备,即我们常说的启动顺序,这个启动顺序是可以在bios中进行设置的,并且我们可以选择具体从哪(软盘、硬盘或可移动设备)启动,比如开机时有一个进bios的快捷键,有一个选择启动项的快捷键。bios按照启动顺序或用户指定的启动项,把控制权交给排在第一位的储存设备,一般都是从硬盘启动。计算机读取该设备的第一个扇区(0柱面,0磁道,1扇区),也就是读取前面的512个字节,即我们通常所说的MBR(主引导记录)。并将该MBR加载入指定位置(0x7c00,关于这个数字的来源,也挺有趣的,可自行google)的内存中去。主引导记录的主要作用是告诉计算机到硬盘的哪一个位置去找操作系统。
主引导记录由三个部分组成:
(1) 第1-446字节:调用操作系统的机器码。
(2) 第447-510字节:分区表(Partition table)。
(3) 第511-512字节:主引导记录签名(0x55和0xAA)。其中,第二部分”分区表”的作用,是将硬盘分成若干个区。
硬盘分区有很多好处。考虑到每个区可以安装不同的操作系统,”主引导记录”因此必须知道将控制权转交给哪个区。
分区表的长度只有64个字节,里面又分成四项,每项16个字节。所以,一个硬盘最多只能分四个一级分区,又叫做”主分区”。通过分区表,我们就可以知道整块硬盘的大致划分
每个主分区的16个字节,由6个部分组成:
(1) 第1个字节:如果为0x80,就表示该主分区是激活分区,控制权要转交给这个分区。四个主分区里面只能有一个是激活的。
(2) 第2-4个字节:主分区第一个扇区的物理位置(柱面、磁头、扇区号等等)。
(3) 第5个字节:主分区类型。
(4) 第6-8个字节:主分区最后一个扇区的物理位置。
(5) 第9-12字节:本分区之前已用了的扇区数。
(6) 第13-16字节:主分区的扇区总数。
最后的四个字节(”主分区的扇区总数”),决定了这个主分区的长度。也就是说,一个主分区的扇区总数最多不超过2的32次方。
如果每个扇区为512个字节,就意味着单个分区最大不超过2TB。再考虑到扇区的逻辑地址也是32位,所以单个硬盘可利用的空间最大也不超过2TB。如果想使用更大的硬盘,只有2个方法:一是提高每个扇区的字节数,二是增加扇区总数。
写到这,忽然对MBR以及分区表很感兴趣,找到了一篇较为详细介绍MBR以及分区的blog–MBR与分区表,通过这篇blog,我们可以知道硬盘是如何通过MBR这个数据结构进行主分区、扩展分区以及逻辑分区的划分的,这时,给你一块硬盘和该硬盘的前512字节(MBR),你就可以自行脑补出该硬盘是如何组织的,有多少块之类的信息。
现在MBR被加载到内存中,通过MBR的结构,我们知道MBR中也有要执行的代码,这与后面怎样将控制权交给操作系统有着密切的关系。
MBR程序段的主要功能如下:
·检查硬盘分区表是否完好。
·在分区表中寻找可引导的“活动”分区。
·将活动分区的第一逻辑扇区内容装入内存。在DOS分区中,此扇区内容称为DOS引导记录(DBR)
这里感觉MBR程序段的功能描写的太过笼统和模糊,带着刨根问底的态度就去找资料,到底载入到内存0x7c00处的代码是什么,找到了一个写的蛮详细的资料–DOS主引导记录扇区:MBR技术详解,里面介绍了MBR程序代码的具体执行。
我们来看MBR是如何完成引导的。计算机读取”主引导记录”前面446字节的机器码之后,如果事先安装了启动管理器(boot loader),则会将控制权交给该启动管理器,然后由启动管理器进行选择启动哪一个操作系统。以grub为例说明启动管理器所做的事情:(图片均从langeldep的blog上截取)







那么grub+用户输入就可以指定具体去加载那个操作系统了,然后将控制权转交给操作系统。
如果事先没有安装启动管理器,我们知道四个主分区里面,只有一个是激活的。计算机会读取激活分区的第一个扇区,叫做”卷引导记录”(Volume boot record,缩写为VBR)。
“卷引导记录”的主要作用是,告诉计算机,操作系统在这个分区里的位置。然后,计算机就会加载操作系统了。
0x03 正片-linux0.11内核分析
以下内容参考了《linux0.11内核完全注释》这本书,并加入了一些本人的理解。好,下面进入期待已久的正片环节。
首先来看一下linux0.11内核的整体结构布局(硬盘上的布局):
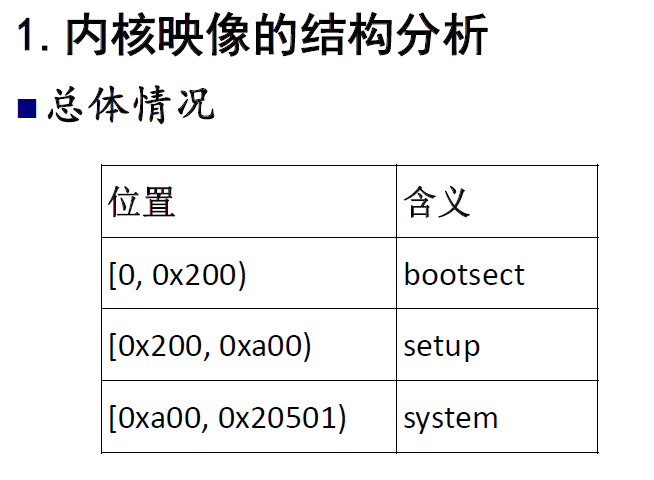
这是img的内容,是在硬盘上存储着的结构,通过上面的分析,我们知道,其实这里的bootsect就是我们前面介绍的MBR,操作系统被装载入内存后,bootsect会被装载在内存的0x7c00处,让我们来看一下此时内存的布局:
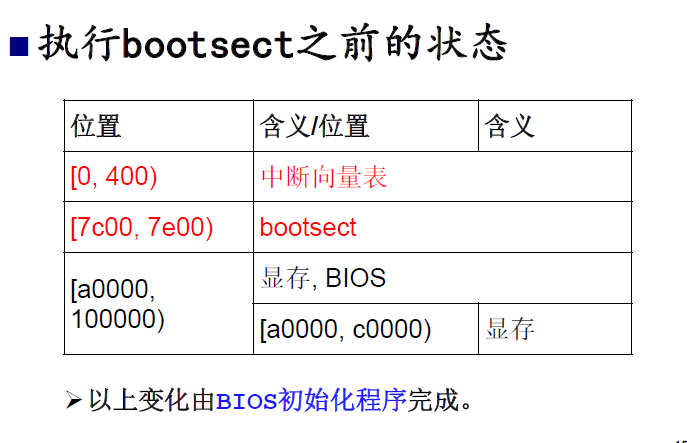
我们就从现在这个布局开始讲起,看操作系统是如何一步步诞生的。。。很多细节我会忽略过去,如果你想去深入挖掘一些东西怎么在代码上体现的,请自行下一份源码去看。
bootsect主要执行复制功能,即把硬盘上的数据给搬到内存上来,以便移交控制权给接下来的指令。执行bootsect后的状态:
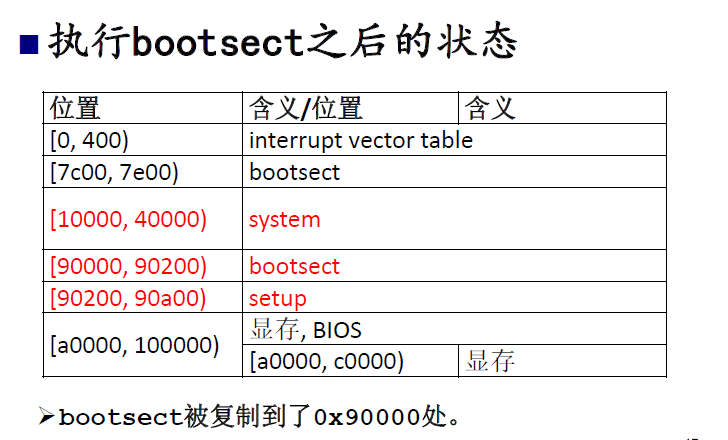
bootsect执行完后,便会将控制权转交给由它搬到内存中的setup指令段去执行,看下setup具体干了哪些事情:

对于将system移动到内存其实位置,这里不过多赘述什么,给出汇编代码:

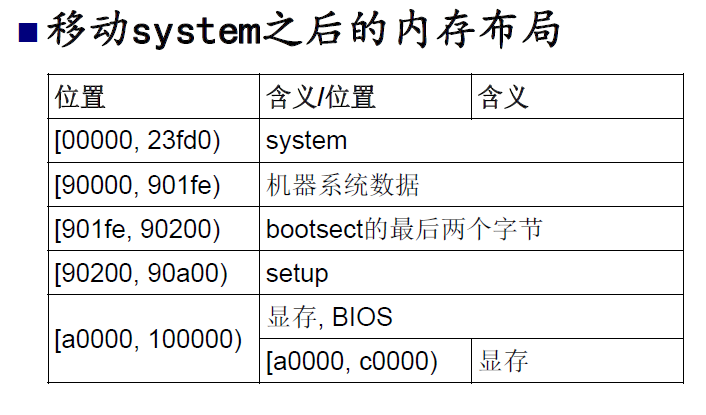
下面我们来看点有意思的事情,就是所谓的段式内存管理,前面说到,setup将system代码移动到内存起始位置后,会去设置中断描述符表和全局描述符表:

设置之前,gdtr(指向GDT的寄存器,存储着GDT在内存中的地址)和idtr(指向IDT的寄存器,存储着idt在内存中的地址),二者均为32位寄存器,关于这两个的作用,下面在讲解段式内存管理时会详细说明:
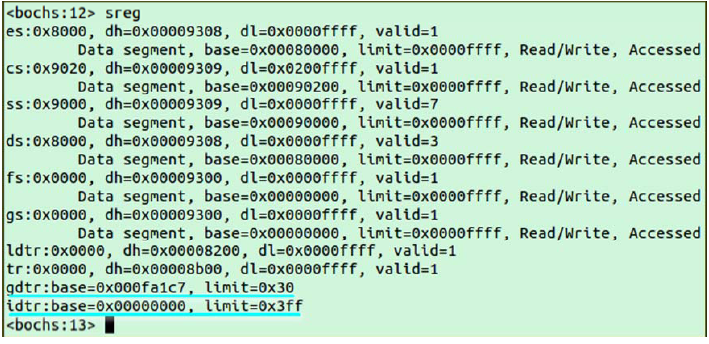
设置之后,两者的值是:
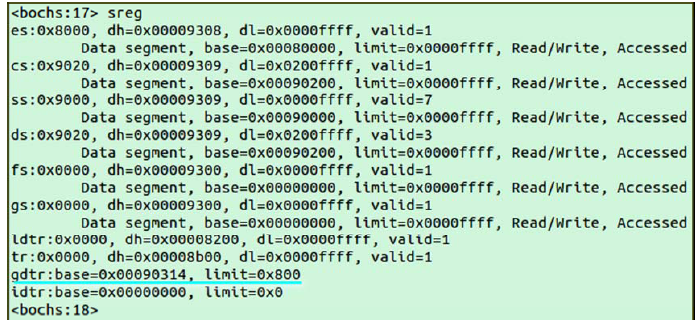
设置完之后,通过如下指令进入保护模式:

进入保护模式后,当再次用地址访问内存时,采用的机制就是段式内存访问机制了,下面来着重介绍下段式内存访问。
段式内存访问
在进入保护模式前,系统采用的寻址方式是实模式寻址方式,这种寻址采用的是段基址加偏移的方式进行访存,段基址存储在段寄存器中,段寄存器有CS(code segment代码段),DS(数据段),SS(栈段),ES(扩展段),还有FS和GS(对于FS和GS不熟,有兴趣自行google),实模式的地址访问很简单,地址形式是段寄存器:偏移(比如:cs:1111),地址的计算规则是段寄存器的值左移4位后作为段基址,然后最后要访问的地址值就等于段基址+偏移,也就是说最后得到一个20位(至于为什么是20位,而非16位,有历史渊源,自行google)的地址值,也就是说实模式下访存的地址范围大小是2^20=1MB,即0-0xfffff。这是实模式下的地址访存方式,在进入保护模式之前,系统都是通过这种方式去访问内存空间。
进入保护模式后,访存就采用段式内存访问了,为什么采用段式内存访问,其中有一个原因就是1MB的内存不够用了,再加上地址线的扩充故引入段式内存访问,段式内存访问可以访问2^32=4GB的内存空间,段式内存访问的地址形式仍然是段寄存器:偏移的形式(比如CS:1111),那么怎么访问到具体的内存空间呢?
首先当系统读到访存指令时,系统会去找GDT,GDT即所谓的全局描述符表,然而系统并不知道GDT在哪,这时系统会去问GDTR(全局描述符表寄存器),前面也说过,GDTR在系统设置GDT时会被初始化,初始化后,GDTR中的值会被设置成GDT的基址,即GDT所在内存的首地址,这里注意GDTR是一个32位的寄存器。GDTR是硬件,在执行访存操作时,系统被设置成会自动从GDTR中取值,从而知道了GDT所在的内存基址,拿到GDT又能怎样呢?别急,在来说一下段寄存器,这里段寄存器在段式内存访问中并不叫段寄存器,而是叫段选择子,且16位空间并非每一位都作为地址,下面来看下段选择子的具体结构

通过段选择子,我们可以得到很多信息,首先系统会查看第2位(从第0位开始算),看他是1还是0,如果是0,则会去查GDT,如果是1,会去查LDT,这里LDT下面会说,我们先不管。好,由于现在还没有设置LDT,故此时访存的话,段选择子的第2位是0,故去GDT中找,而通过上图我们知道,第3-15位共13位为index,即GDT的索引值。为什么需要索引值呢?GDT叫做全局描述符表,既然是个表,那这个表就是由一个个的单元构成,而这些所谓的单元就是全局描述符,看下全局描述符(一个很典型的代表就是段描述符)的结构:
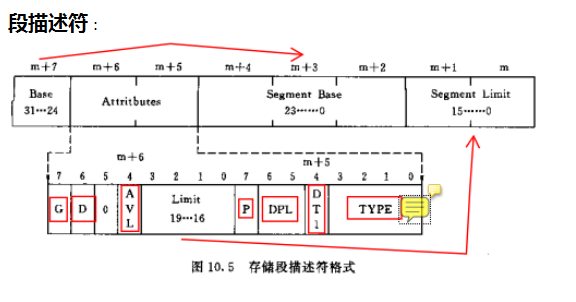
对全局描述符表的解释:

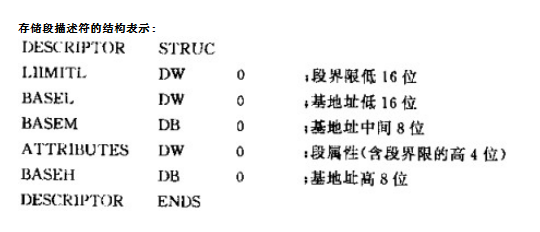
这里解释一下,全局描述符包括很多类型的描述符,不同的描述符描述的对象不同,描述段的叫段描述符,描述门的叫门描述符,当然典型的就是段描述符了,下面主要针对段描述符讲解段式内存访问。
通过上图我们可以看到,每个描述符所占的空间是64位,即8字节,且每位代表着不同的意思,前面提到,段选择子的前13位代表着GDT的索引值,即段选择子所要选择的段的描述符在GDT中相对于GDT基址的偏移,这里的偏移步长是8字节,这样我们就可以通过段选择子拿到要访问的地址所在的段的一些最基本的信息,比如该段在哪,段限是多少,什么段,是否可执行等等
有了这些姿势,我们来大致总结下段式内存访问的流程:当进入保护模式后,如果系统执行到访存指令时,会把指令中要访问的内存地址以段选择子:偏移的形式(实际的地址也是这么给的)给拿出来,然后通过段选择子(假设还未设置LDT)知道要去找GDT,这时系统就会从GDTR中取出GDT的基址,然后在根据段选择子的3-15位知道描述符相对GDT基址的偏移,此时别忘了段选择子还有一位RPL位,然后系统会根据此位与找到的段描述符的DPL位进行一个check,如果check通过(关于具体是怎样check的,推荐一遍blog–保护模式特权级别DPL,RPL,CPL 之间的联系和区别),系统就知道当前是有权访问该段的,然后就可以拿到相应的段描述符了,通过该描述符可以知道要访问的地址所在的段基址,在得到最终地址之前,系统还会将段选择子:偏移中的偏移与段限进行比较,段限根据粒度位进行相应的粒度扩展后,若偏移不超过段限,就可以通过段基址+偏移地址的形式得到最终要访问的地址了。这里说明一下,这里得到的地址是线性地址,在未启动页式内存管理之前,该线性地址就是真正的物理内存地址,
段式内存访问的姿势差不多就这些,但是不知道你有没有发现,此种内存访问的效率并不是很高,因为每次访问内存单元时,都需要去先访问一下GDT,找到要访问的段,然而根据代码的局部性原理,我们可以知道,不管是数据还是指令,在一段时间内它的地址应该都是处在一个段的,所以说这里是可以优化的。现实中的优化使用的是硬件方面的优化,也就是直接对于每个段选择子,给他配套了两个影子寄存器(dh和dl),两个都是32位寄存器,加起来正好可以存储一个段描述符,用于存储根据当前段选择子而对应的段描述符,这样的话,在访问同一个段的地址时,就不需要去再次访问GDT了,可以直接在影子寄存器中直接取得该段对应的描述符的值,然后执行接下来的访存操作,只有当访问不同的段时,操作系统会识别出要访问的地址的段选择子与当前寄存器中存储的段选择子不同,操作系统就知道要更新相应的影子寄存器了,然后就会去通过该选择子访问GDT并拿到相应的段描述符装载入影子寄存器中,实现刷新影子寄存器的操作,以便下次访存使用。
下面我们再来看刚才图中比较有意思的两个汇编指令:
lmsw ax;和jmpf 0x0008:0000,对于lmsw指令,该指令主要是针对控制寄存器的汇编指令(控制寄存器有4个cr0-cr4,x86_32的CR0为32bit,X86_64下为64bit,相关姿势请自行google),上面的mov ax,0x01;lmsw ax实际上是将ax的值装载入cr0寄存器中,此时cr0寄存器的最低位为1,其余为是0,最低位对应着PE(protect enable)为,置1代表着保护模式开启(对于cr0中各位的含义,自行google)。接着看jmpf指令,是一个远跳转指令,从此步指令开始就使用了段式内存访问机制,对应着保护模式的开启。
段式内存访问就讲到这,我们接着来看操作系统的执行流程
进入保护模式后,setup代码的使命就算是完成了,下面setup会将控制权转交给head(system的一部分),来看下head干了些什么:

上图描述的是不全面的,在进入head后,首先会设置段寄存器和栈指针,以保证访存操作的快速性和正确性,然后才会去设置IDT和IDTR,具体的指令就不po图了,设置后ds,ss,fs,gs四个寄存器的值,它们指向的GDT 的2 号描述符的信息是:低长字为0x000007ff,高长字为0x00c09300。其含义是:段基址为0x00000000,段限长为0x00800000(=0x007fffff+1),类型是数据段,可读写,然后设置ss和esp,设置之后ss 被赋予了值0x0010,与ds 同值,都指向GDT 的2 号段描述符,esp 被赋予了值0x0002125c,回忆一下,system 的bss 段的地址范围是[0x1fb20,0x23fd0),可见现在ss:esp 所指向的线性地址0x00022f00 位于system 的bss 段内,是数组user_stack 结束之后的第一个字节的位置。可见现在user_stack 被用作栈(向下增长),因为现在CPU 的CPL 为0,所以CPU 目前工作在核心态,上述栈现被用作核心栈。user_stack 的位置如下:

然后去设置IDT和IDTR
有了段式内存访问机制的基础后,中断执行的流程就较为简单了,给出设置IDT的代码

中断处理机制
下面介绍中断机制:不管是实模式还是保护模式,中断操作都是通过本质上int+中断号的指令实现的。在实模式下,中断机制较为简单,采用的是中断向量表,该中断向量表由bios加载完成,主要用于bios下一些工作的完成,实模式下的中断向量表存储在内存[0,400)共1KB的内存空间中,每个中断向量占用4个字节,中断调用指令int+中断号指令中的中断号就对应着中断向量表的索引,中断号的索引步长是4字节,这里每个中断向量并非直接存储着中断处理程序对应的物理地址,我们知道实模式下访存操作采用的是段值 * 16 + 偏移值的形式,所以这里的中断向量的四个字节,2个字节存储段值,另外两个存储偏移值,然后根据实模式下的地址计算公式就可以找到该中断号对应的中断处理程序所在的内存地址,找到地址后,就可以在简单的保存现场后,将控制权转交给中断处理程序了。在保护模式下,中断调用指令依然是int+中断号的形式,而系统采用了另外的一套流程去找寻该中断号所对应的中断处理程序,保护模式下采用的是中断描述符表,其表项——中断描述符可以是中断门、陷阱门和任务门中的一种。我们知道system整体被移到了内存的起始地址处,覆盖了原先的bios中断向量表。设置完中断描述符表以及中断描述符表寄存器(IDTR,32位,存储IDT的基址)后,内存粗略布局为:
操作系统在处理具体的中断指令时,具体查找中断处理程序的流程用一张表概括为:
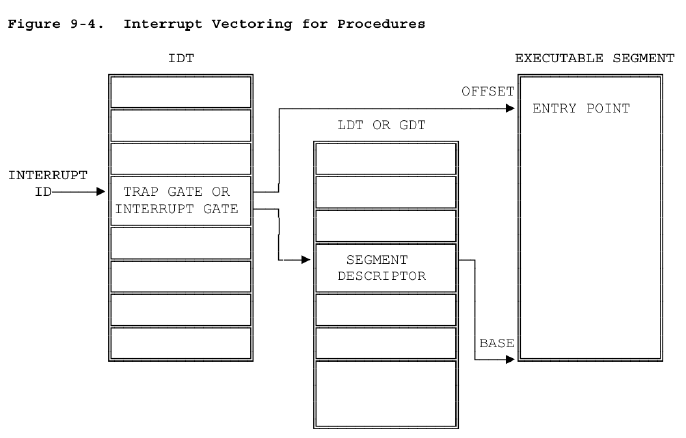
总结下,首先系统通过中断指令拿到中断号,然后从IDTR中拿到IDT的基址(现在是0x54c0),然后根据中断号*步长(8字节,每个描述符大小是8字节)得到偏移,通过基址+偏移拿到该中断号所对应的中断描述符(通常是中断门或陷阱门),中断描述符的结构为:

通过该结构,我们可以看到描述符存在着选择子和偏移以及一些标志位和保留字,然后通过该选择子可以去GDT或LDT中找到相应的段描述符,然后拿到段描述符后,在根据刚才中断描述符的偏移得到中断处理例程入口在该段中的偏移,从而就找到了该中断号所对应的中断处理例程。
设置完IDT以及IDTR之后,保证了系统可以正常执行中断指令了。然后系统又会去设置GDTR,这里为什么又去设置GDTR呢?在设置之前,我们知道,原来GDTR的值是0x00090314,按照个人理解,一是此时GDT所在的位置距离system太远,二是以前的GDT并不能再满足需要了,可以这么说,前面设置GDTR寄存器是为了实现系统的段式内存访问机制,根据前面的注释“load gdt with whatever appropriate”可以知道。在执行完jmpf指令后,系统的控制权就交给了system的head,很明显,为了方便,需要给system在开辟一块空间当做system的GDT,他选择的是[0x5cc0,64c0),紧靠着IDT的一段内存,然后设置GDTR指向这里,所以设置完GDTR的值后,GDTR的值就是0x5cc0了,新的GDT表为:

可见只有1 号和2 号描述符是有效的,它们分别描述了一个代码段和数据段,0号描述符始终是0,做保留用,接下来在生成新的段时,就会在GDT中添加相应的描述符,3号4号之类的。既然重新设置了GDT,那么段寄存器的值就需要重新设置了,可谓一朝君子一朝臣啊(小感叹一下),毕竟执行流掌握在谁的手中谁说了算。。。重设寄存器的指令就不po图了,设置后除cs 外,cs还是0x08,其他段寄存器都获得了新值0x10,段限长变为了0x00ffffff(原来是0x007fffff)。
到这里,操作系统已经实现了段式内存机制以及中断机制,接下来又是一些有意思的指令:
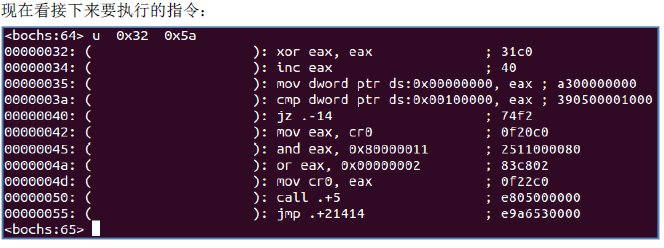
这段代码首先测试A20 地址线是否打开,然后检测数学协处理器是否存在。
关于A20地址线以及数学协处理器又是挺有意思的历史,感兴趣的话就去google。
马上,还有一个函数的执行(setup_paging函数),head就快完成它的使命了,接下来的指令:
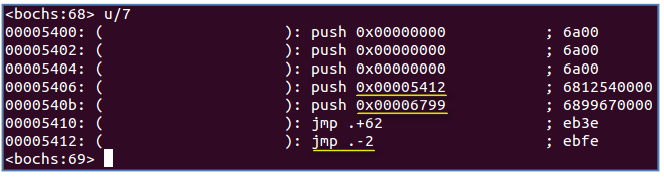
先是往栈中压入三个参数,再压入返回地址0x5412,再压入返回地址0x6799(main 函数的入口地址),然后执行jmp 指令跳到setup_paging 函数(0x5412+62)中去执行。在setup_paging函数执行完返回时,会返回到0x6799(即main)函数中去执行,main 函数原理上应该不会返回,如果万一返回,就返回到0x5412 中去执行,而在0x5412 处是一个跳到自我的jmp指令,会进入无限循环。
我们来看setup_paging函数的执行,即head的最后一个工作——设置页目录表和页表。
我们先来看系统是怎样一步一步的设置的,然后在来介绍页目录和页表有何作用。
具体设置流程,看下setup_paging函数对应的具体代码:
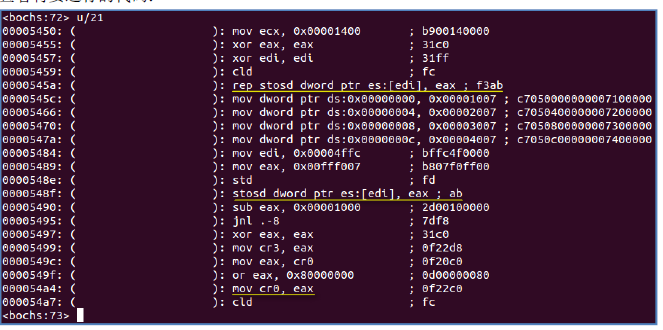
这段代码的功能是设置页目录和页表,然后启用分页机制。查看一下head.s 的源代码可知,目前内存[0, 0x5000)对应于程序中的pgdir、pg0~pg3 这些标号,从而可知,0 号页帧(其物理地址范围是[0,0x1000))是页目录,1 号到4 号页帧是4 个页表,设置完页目录表和页表后,内存布局为:
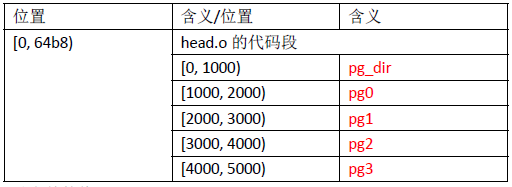
页目录(pg_dir)可以理解为1级页表,页表(pg)可以理解为2级页表,实际上就是两次跳板
设置完后,页目录中设置了4个页目录项(上面的四条mov指令),其余的页目录项(共1024个页目录项,因为一个页4KB,而一个页目录项4字节)都是0,第一个页目录项的内容为0x00001007,其含义是:0 号页表的物理地址是0x1000(对应pg0),页存在,可读写。其他3 个页目录项类似。因为一个页表包含1024(=0x1000/4)个页表项,可以描述4MB(=1024*0x1000)的空间,所以上述4个页表项总共可以描述16MB 的空间,而我实验用的bochs虚拟机的内存只有16MB,所以只设4 个页目录项就够了。
接下来是pg的内容,以pg0为例,pg0 中的第一个页表项的值为0x00000007,其含义是:这个页表项所对应页面被映射到起始地址为0x00000000 的物理页帧,即0 号页帧,页存在、用户可读写;第二个页表项的值为0x00001007,对应物理页帧的起始地址为0x00001000。可见按此页目录,每一个线性地址都被映射到了与自身相等的物理地址,即所谓“identity‐mapping”(对等映射,源代码注释中的用语)。
好了,现在页目录表和页表已经设置完毕,但操作系统并不知道pg_dir的基址在哪,所以需要一个东西来记录一下,这就是cr3寄存器(页目录基址寄存器),接下来的指令就是给页目录基址寄存器cr3 赋值,因为页目录pg_dir 的地址是0x0000,所以将0 存入cr3,但此时系统并不承认开启了分页机制,因为还要设置相应的标志位,还记得我们前面说的cr0寄存器吗,它的最后一位是PE位,用于标识是否开启保护模式,对应的cr0的最高位是PG位,用来标识是否开启分页机制,所以接下来的指令就是去将cr0的PG位置为1,告诉操作系统,分页机制开启,接下来访存就需要结合分页机制了。但是,现在的情况比较特殊,因为页目录和各页表的设置是对等映射,线性地址与物理地址相同,所以后面的访存操作实际不受影响。
执行完上述指令后,接下来就是一条ret指令,还记得刚进入该函数前栈的布局吗?此时栈顶存储着main的入口地址,所以执行完ret后,控制权就交给了system中的main,然后系统就进入main执行。在进入main之前,此时的内存布局和状态是:
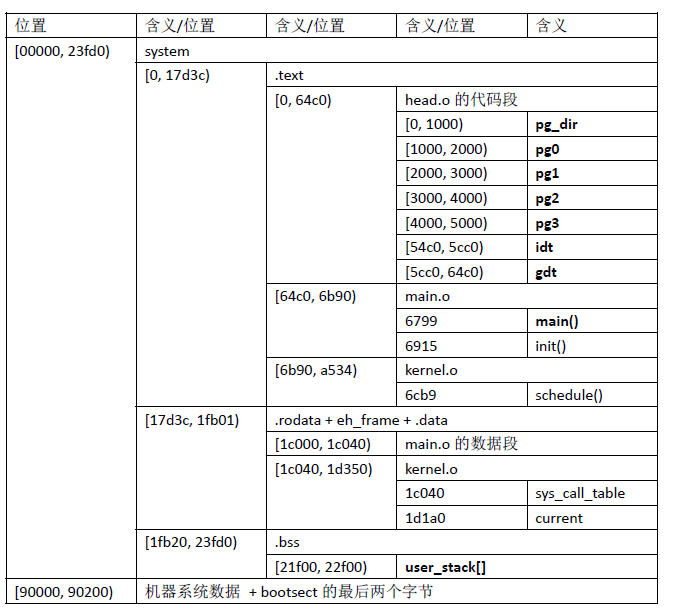

到这,我们即将进入main的讲解。但是,不觉着少点什么吗?没错,那就是分页机制的具体作用还没有讲解,下面我们来一探究竟
引入分页机制后的访存
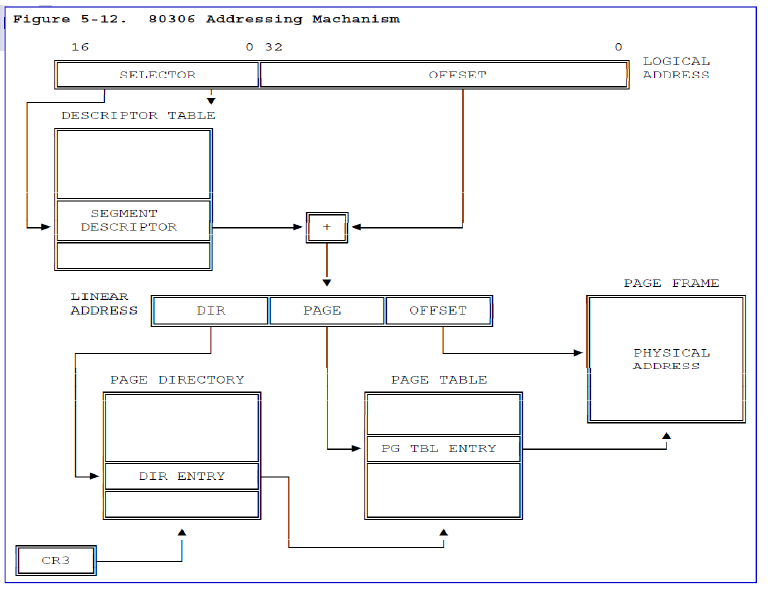
还记得我们前面所说的,给定一个逻辑地址,经过段式内存转化后,会得到一个线性地址,在为开启分页机制的情况下,该线性地址即对应着物理地址。但,此时已开启分页机制,所以说此时线性地址到物理地址仍需要进一步的转化。
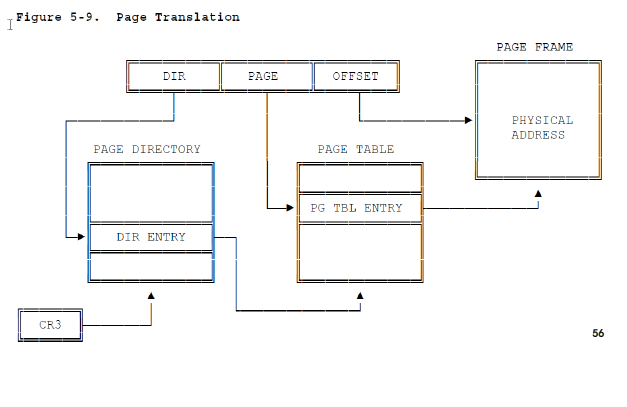
根据上图我们可以看到,对于拿到的线性地址,它包含着三个信息,DIR(31-22,共10位),用于访存页目录偏移,PAGE(21-12,共10位),用于访存页表偏移,OFFSET(0-11,共12位)用于访存页内偏移,下面在给出具体的页目录项和页表项的结构和各字段的含义:
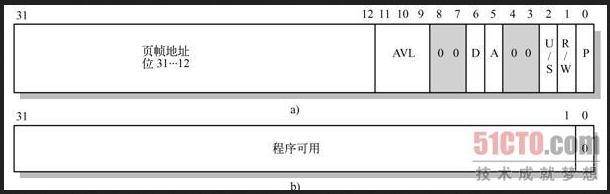

下面来总结下如何由线性地址结合分页机制转化为物理地址的。拿到线性地址后,首先会查看cr0寄存器,看是否开启了分页机制,如果没有,则该线性地址就是最终的物理地址,如果开启,则会取该线性地址的前10位,然后在cr3中拿到页目录的基址,这前10位(DIR)就对应着页目录的索引值,根据基址+DIR*4的结果可以找到对应的页目录项,通过该页目录项可以找到对应的页表的基址,同样拿到页表的基址后,同样的根据PAGE(偏移)可以找到所在的具体的页,找到具体的页后,可以根据OFFSET,找到真正的物理地址,这样就完成了线性地址到物理地址的转化。
具体的由逻辑地址转化为物理地址,可以表示为:
到这就算说完了一部分内容,接下来进入main。
main的执行过程
程序main.c 是用C 语言编写的,还是和以前一样,先看main具体干了那些事情:

首先我们来看主内存区的初始化。进入main之后,首先会计算内存缓冲区的结束地址buffer_memory_end 和主内存区的开始地址、结束地址。内存缓冲区用于外设数据缓存,主内存区用于分页管理,也就是说主内存区之外的区域是由内核直接访问的。内存缓冲区之后的第一个字节的地址是0x400000(4MB),它也是主内存区的开始地址,中间没有设虚拟内存盘。整个内存之后的第一个字节的地址是0x1000000(16MB)。主内存区的位置是:[400000, 1000000)。计算完内存缓冲区以及主内存区的相应地址范围后,就需要进行初始化了,以便进行接下来的操作和管理,4MB之前的空间被操作系统默认是使用过的,接下来我们看如何初始化主内存区的,通过函数mem_init来实现。函数mem_init 的作用是对数组mem_map 进行赋值。mem_map 位于system 的数据段中,再未初始化时的取值全为0。这个数组在内存布局中的位置是:

数组mem_init 共包含3840(0xf00)个元素,每个元素描述一个页帧的分配情况,它可以对内存的后 15MB 的页帧进行描述,每个元素(1字节,8位)描述一个页帧,所以说3840个元素可以描述的空间范围是384041KB=15MB,在mem_init函数完成初始化操作后,内存区域[0x100000, 0x400000)所对应的页面在mem_map 中的标志被置为了0x64(=100),表示已被使用(实际被内存缓冲区使用),内存区域[0x400000, 0x1000000)的区域则在mem_map 中标注为了0x00(表示未使用)。它们的交界点0x209c0 是数组中下标为0x300(=0x209c0‐0x206c0)的元素,对应于0x100000 开始的第0x301 个页帧,也就是内存地址为0x400000(=0x100000+0x300*0x1000)的页帧,也就main_memory_start 的值。对主内存区初始化之后,是对陷阱门、块设备、字符设备、tty 设备和时间的初始化,这些内容我不是很熟,所以就不误人子弟了,我们暂时跳过这部分内容,以后需要时再分析。
然后进入调度程序的初始化,即sched_init函数的执行,这里所谓调度程序,是指进程(一般是windows的说法,linux下一般叫任务,以下不区分这两个概念)的调度,从这里开始,操作系统就要开始建立起进程(任务)的概念。
在sched_init函数中,设置GDT 中的TSS(任务状态段)描述符、LDT 描述符(前面提到过),并初始化task数组(这里说明下,我们现在是跟着代码走,至于为什么要建立这些东西以及这些东西的作用,下面会详谈)。GDT 的4 号、5 号描述符分别被设为指向0 号进程的TSS(init_task.task.tss)和LDT(init_task.task.ldt),后续的描述符都被初始化为0,其中6 号、7 号描述符以后将被设为指
向1 号进程的TSS 和LDT,依此类推。而任务指针数组task[]的第一个元素已被初始化为指向0 号进程的tast_struct 结构,后续的每个元素都被初始为空。现在的GDT中只有两个描述符,1 号和2 号描述符是有效的,分别描述了一个代码段和数据段,它们是在head.s文件中初始化的。首先来看task 数组,它是一个指针数组,task 数组占据的内存空间是[0x1d1c0, 0x1d2c0),(对于task数组的索引,不需要借助相关的硬件,因为前面已经准备好了C的环境而且main本身就是用C写的,所以操作系统若想知道task数组的位置,可以在代码中直接访问这个变量就好,这也是C的便利之处)是一个包含64 个元素的task_struct 指针数组,且只有task[0]被赋值0x1c1a0,其他都是空指针0x0。task[0]是0 号进程的进程控制块指针,查看源程序可以知道:它存储的实际上是变量init_task 的地址,0 号进程的控制块就是init_task。讲到这,可能大家已经有点晕了,反正我第一次听的时候是有点晕的,这里,我们要能清楚各个数据结构之间的关系,po几张图:

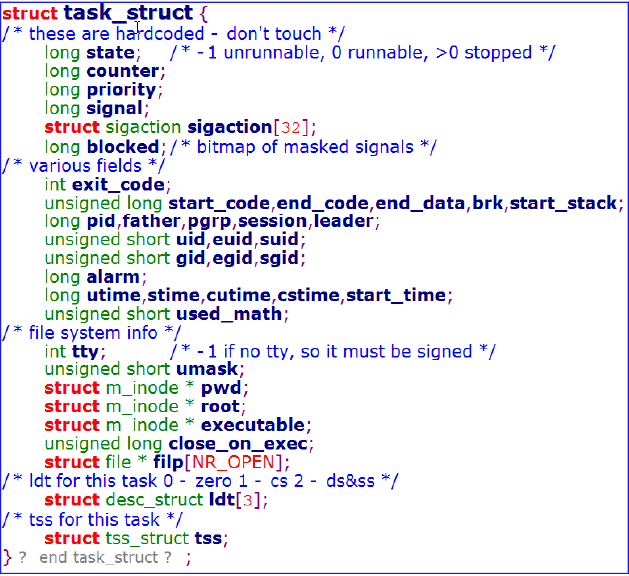
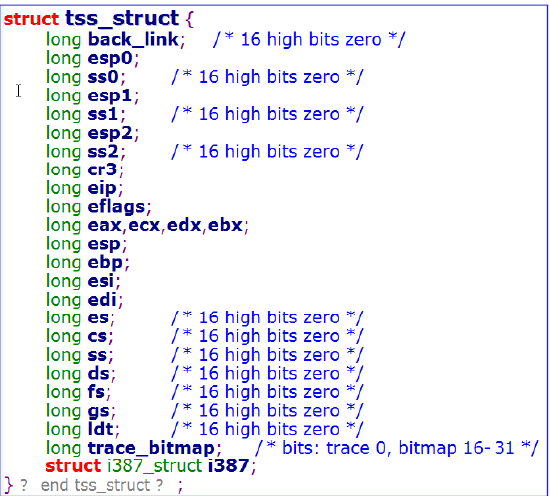
从这几张图就可以看出这几个数据结构的从属关系,首先系统在建立每个任务时,会为每个任务建立一个联合数据类型,即task_union这个数据结构,由联合类型的特性我们可以知道,task_union的大小是4KB,我们来看他的两个成员,一个是task_struct,一个是stack,这两个成员共享这4KB的空间,task_struct上面有图,用于存储任务相关的信息,stack是该任务的内核栈(用户栈的话,前面有提到过),两者共享这4KB的内存其实并不冲突,因为栈的低地址方向生长性(栈空时栈顶指针指向该页面的末尾),所以只要栈不过分生长就不会覆盖task_struct了。由上图还可以看出,task_struct包含tss_struct,而tss中存储着任务调度和切换的重要信息(后面会谈)。
理清了这些数据结构的关系后,我们接着谈。init_task 的前面956 字节用于进程0 的控制块,后面的3140 字节用于内核栈。task 数组和init_task 在内存的位置:

接着跟着代码走,下面会向GDT中增加两个描述符:4 号和5 号描述符(从0 开始编号)。4 号描述符的含义为:段基址为0x0001c488,段限长为0x00068,DPL 为0 级。这正是init_task.task.tss 的位置和长度,init_task.task.tss 总共有212 字节,但除去最后一项(i387)以后,刚好占104 字节,5 号描述符与4 号描述符类似,描述了init_task.task.ldt 的位置。具体的,对于TSS段描述符各个位的含义,可看这篇blog——TSS描述符,对于LDT描述符各个为的含义,可看这篇blog——x86架构下的系统段描述符格式
进程结合LDT的访存实现
相信看到上面,很多人已经开始骂了,这TM什么TSS,什么LDT,说清楚点啊。。。下面我们就来谈谈进程它到底是个什么鬼,也只是个人的一些见解。操作系统引入进程的概念的原因:从理论角度看,是对正在运行的程序过程的抽象;从实现角度看,是一种数据结构,目的在于清晰地刻画动态系统的内在规律,有效管理和调度进入计算机系统主存储器运行的程序(from baike)。接触过计算机的人,都会有进程的模糊认识,但并不能准确的说清进程是什么,这里我们也不讨论进程是什么,因为这就像讨论鸡是什么一样无聊,进程就是进程。对于进程,系统每建立一个进程就会向task这个数组中添加一个元素,相当于注册,这个元素指向task_union这个数据结构,这个数据结构有两个成员,一是该进程的相关信息,二是该进程的内核栈。进程分用户态和内核态两种,我们讨论到这,此时的操作系统只是单进程且处于内核态,并未进入用户态,权限还很大,我们暂且称该进程为0号进程。每个进程都有一个task_struct结构,这里我们只关心它其中的tss以及LDT,tss用于进程切换,LDT用于当前进程的访存。首先说LDT,有了GDT的基础,LDT也不难。引入LDT,个人认为,一是为了更好的体现进程的独立性,二是更好的体现GDT的全局性。每个进程可能不只两个段,而GDT只有256个描述符的空间,我们知道,task数组在声明时有64个元素,也就是最多可以有64个任务,显然GDT已经不能满足需求,而且试想每一个任务的每一个段描述符都存储在GDT中,那将会是一个多么混乱的事情,且在实现进程切换时,也会有相应的困难,所以,对于每个进程,操作系统只在GDT中注册两个描述符TSS和LDT,且针对这两个描述符,都有相关的硬件寄存器(TR和LDTR)指向这两个描述符。有了LDT,我们来看,针对进程,它是怎样实现段式访存的。首先,每个进程都有一个LDT,专门用于描述该进程所用到的段的信息,在访存时,进程给出访存地址,段选择子:偏移的形式,由段选择子的第2位知道要去LDT中找相应的描述符,段选择子中的index代表该段在LDT中的偏移,但是OS并不知道LDT在哪,此时就需要借助硬件LDTR来寻找LDT了,对于LDTR的结构,给出如下图:

LDTR由显式的16位和隐式的64位(类似于前面介绍的影子寄存器的概念)构成,对于显式的16位,存储的是LDT描述符在GDT中的索引,也就是说,访存时,首先通过判断得知要访问LDT,则会从LDTR中取出LDT描述符在GDT中的索引,用过判断该描述符的S字段位和type字段位的含义,得知是LDT描述符,然后会将该描述符的内容存储到LDTR的隐式64位上,以便加速下一次的访存,通过该LDT描述符记录的信息,找到该进程对应的LDT(局部描述符表),LDT中存储着该进程所需的所有段的信息,然后通过最早给的段选择子:偏移中的段选择子的index部分找到要访存的地址在LDT中的位置,如果是第一次访问,则会把该描述符的信息存储到相关的段描述符的影子寄存器中,以加速访存,根据描述符的信息,找到要访存的地址所在的段基址,找到后,进行相应的check,允许访问后,可以用段基址+偏移的形式得到访存的线性地址,然后看是否分页,得到最终的物理地址。这里是有两层优化的,首先针对不同的进程,用LDTR的影子寄存器实现优化,在访问相同进程时,可直接从LDTR的影子寄存器中取出该进程的LDT描述符,对于同一进程的不同代码段或不同数据段,使用了段寄存器的影子寄存器进行优化。也就是说,如果两条指令在同一个进程的同一个代码段,则可以直接去访问段寄存器的影子寄存器得到段信息,省略了先访问GDT在访问LDT的步骤。这里针对给出的访存地址是否是不同进程以及是否是不同段的检测的话,对于不同进程,是在实现进程切换时实现的LDTR的刷新,对于段,比较给出的访存地址的选择子与现在的段选择子是否不同,不同则根据信息实现影子寄存器的刷新。到这,就算把加入进程以及LDT后,访存的实现讨论完了。。。
我们接着跟着程序的流程走,对于TSS的讨论,等到操作系统实现多进程以及有进程切换的相关操作时再具体介绍。紧接着会将EFLAGS 寄存器中的NT 标志置零,对于EFLAGS各位含义,给出blog—— x86—EFLAGS寄存器详解 ,再接下来程序会将进程0的TSS 段描述符(即GDT 的4 号描述符)的选择符加载到任务寄存器TR中,通过ltr(0)指令实现,ltr(0)指令会将段选择符_TSS(0)加载到TR 寄存器中。分析一下,_TSS(0)的值0x20,指的是GDT 中的4 号描述符。由前面的程序可知,该描述符指向init_task.task.tss,即进程0 的任务状态段(TSS)。TR会被赋值为0x20,此选择子的含义:目前的TSS 由GDT 中的4 号TSS 段描述符
指定,本选择子的RPL 为0 级。在TR 的影子寄存器中已经加载了GDT 的4 号描述符的值,即高长字为0x00008b01,低长字为0xc4880068。这与我们在前面看到的是基本一致的,唯一的不同是原来的“89”变成了现在的“8b”,原因在于TSS 段描述符中的忙标志B 被置位,表示该任务(进程0)处于忙状态,即正在执行或正等待执行。接下来会对LDTR赋值,0x28会被赋值给LDTR 寄存器,这个选择符指向GDT 中的5 号段描述符,后者指向进程0的LDT,即init_task.task.ldt。接下来,设置8253 定时器,使它每10 毫秒发出一个时钟中断信号,即每10毫秒执行一次时钟中断处理程序。接下来是设置时钟中断处理程序对应的中断门,通过阅读源码可以知道,会将idt 中的0x20 号描述符设置为一个中断门描述符,指向中断处理函数0x08:addr,代码段值0x08 意味着cpl 将变为0 级,中断门的dpl 设为0 级,意味着在用户态(3 级)不能直接调用这个中断门。因此,当32 号(0x20)中断发生的时候,会执行的中断处理函数是代码段中的timer_interrupt 函数,且cpl 会是0 级,即进入核心态。原来0x20 号描述符指向的处理函数地址是0x08:0x80b5,查符号表可知这是函数reserved的入口地址,追根溯源,该函数在文件asm.s 中定义,对idt 的上次赋值在trap_init 函数中,目前idt 的0x20 号描述符是一个陷阱门,好,不去管它。设置完后,0x20 号描述符会被改为指向地址0x08:0x7724,也就是timer_interrupt 函数的入口地址。接下来会修改中断控制器屏蔽码,允许时钟中断,也就是说接下来每10毫秒会进行一次时钟中断,执行timer_interrupt 函数。接下来设置idt的0x80 号描述符,使其变成一个陷阱门,指向中断处理函数system_call(系统调用总入口函数),且门的dpl 被设置为3 级,即允许用户态程序调用这个中断。这里无论是调用set_intr_gate 还是调用set_system_gate来设置,描述符中的段选择符都是0x08,即使用GDT 的1 号段描述符,且cpl变为0 级,因此响应这些中断时内核都将进入核心态。设置完后,0x80 号描述符已经由原来的指向0x5428(函数ignore_int)变为了指向0x764c(system_call),且原来的8e 变成了ef,意味着由中断门变成了陷阱门,dpl 由原来的0 级变成了3 级,这些都可已通过分析门描述符的格式得出,对于门描述符的介绍,参考blog——门描述符1以及blog——门描述符2。
这里需要说明一下,我们对源码进行简单修改,通过增加系统调用的方法增加一个显示函数,以便下文研究进程切换时能够直观的显示出来,修改如下:设置idt 的0x81 号描述符,使其指向中断处理函数display_interrupt,这是一个我们新加的处理函数,用来向屏幕上输出一个字符。
总结下sched_init函数对各个描述符表的修改:

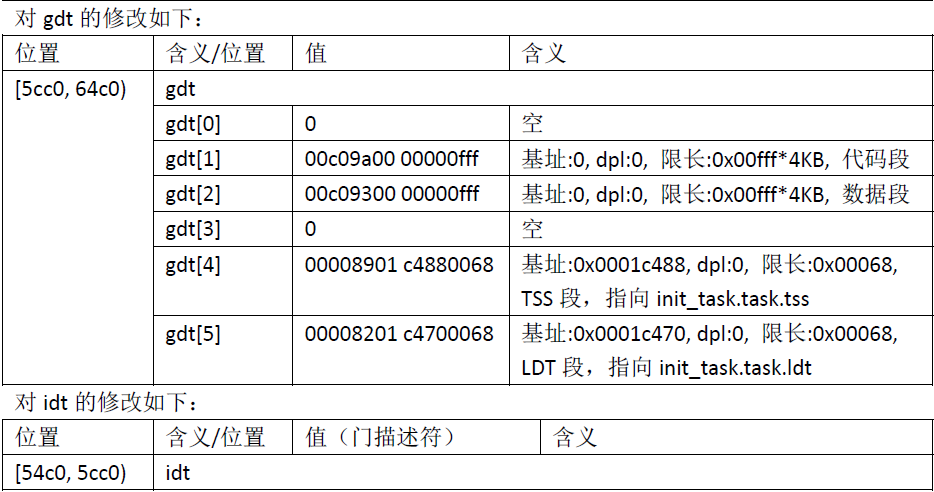

接下来进入buffer_init函数,是对内存缓冲区的初始化,前面mem_init函数是对主内存区的初始化,两者要区分开,内存缓冲区的范围是:[start_buffer, buffer_memory_end),即[0x23fd0,0x400000),这部分缓冲区会分成两部分:后面是按1024 字节为单位划分的缓冲块,前面是用于管理缓冲块的缓冲头,两者一一对应。我们来看buffer_init函数执行完后,内存缓冲区的变化:
首先查看内存缓冲去开始部分的变化:

内存范围[0x23fd0, 0x23ff4)是一个缓冲头,对应于缓冲块[0x3ffc00, 0x400000),它的后一个缓
冲头的起始地址是0x23ff4,它的前一个缓冲头(也是最后一个缓冲头)的起始地址是0x42444。
所有的空闲缓冲块的缓冲头构成了一个双向循环链表。再查看最后一个缓冲头:

可见它对应的缓冲块是[0x42800, 0x42c00),它的前一个缓冲头的地址是0x42420,后一个缓冲头的地址是0x23fd0,即第一个缓冲头。空闲缓冲块的缓冲头链表的头指针存在变量
free_list 中。可见,基本验证了我们前面说的,内存缓冲区划分成两部分的说法。我们把内存缓冲区的结构总结下:1.每个缓冲头占36字节大小,即9个双字大小,从0x23fd0开始,每36字节是一个缓冲头,到0x42468结束,共(0x42468-0x23fd0)/0x24=D76=3446个缓冲头,管理着3446个缓冲块,对于缓冲头的结构,我们将9个双字节按照从低到高的顺序,用0-8代表,对于一个缓冲头,第0个双字存储着该缓冲头管理的缓冲块的起始地址,第7个及第8个双字用于组织缓冲头的双向链表(有点像堆中的空表),第7个双字存储着前一个缓冲头的内存地址,第8个双字存储着后一个缓冲头的地址,其余双字代表的含义未知,缓冲头的管理方式是从后向前索引缓冲块,即双向链表的表头的缓冲头管理处于最高地址的缓冲块,然后依次向低地址递减,即倒着的;2.每个内存缓冲块的大小是1024个字节,缓冲块的起始地址是0x42800,结束地址是0x400000,共(0x400000-0x42800-(0x100000-0xa0000)(显存和bios))/1024=D76=3446个缓冲块,正好是一一对应的。我们前面提到过,内存缓冲区主要用于外设缓存数据,为了快速查找包含指定设备的指定逻辑块的缓冲块,包含数据的缓冲块的缓冲头被按照hash 表的形式组织起来,相应的hash 数组名为hash_table,在刚初始化完后,这个hash 数组中没有链接缓冲头,每个数组元素都是空。下面总结下,在初始化内存缓冲区后,内存的布局:
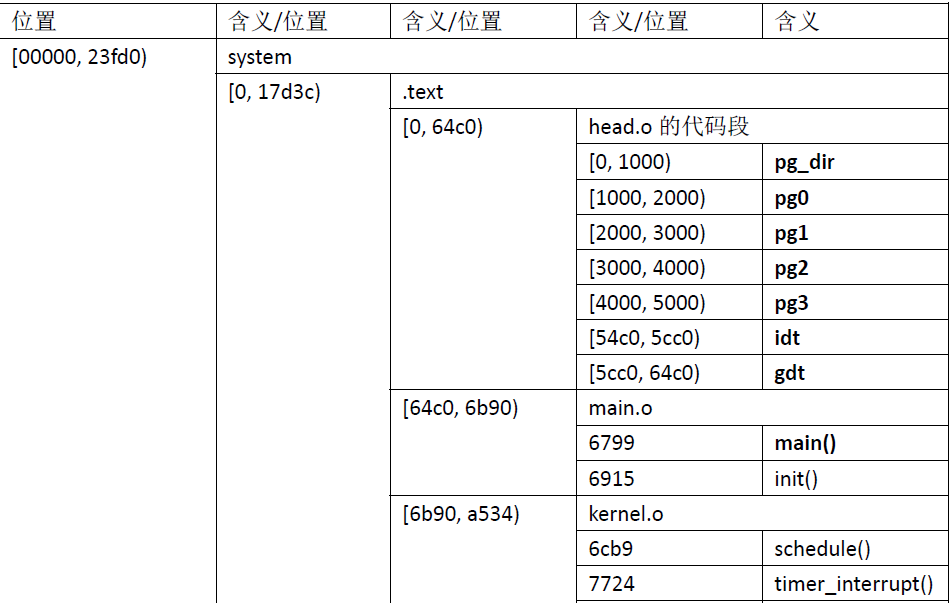

接着跟着代码走,接下来是hd_init函数,此函数是对硬盘和软盘进行初始化,对这块不熟,这里略过不看,有兴趣的自行google,接着会执行move_to_user_mode(),其实move_to_user_mode()是一个宏,给出该宏的定义:
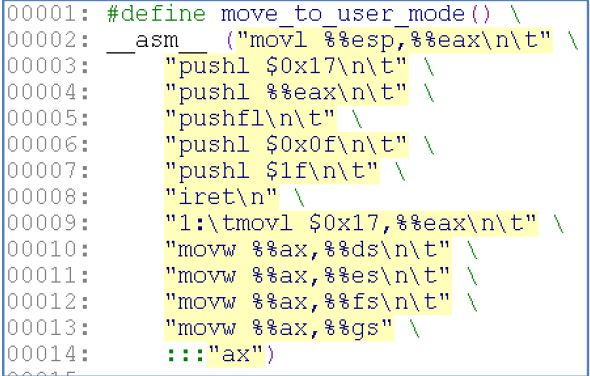
这段程序首先向栈中压入段选择子0x17、当前的栈指针、eflags 寄存器的值、段选择子0x0f,以及标号1 的地址,然后执行iret 指令。在未执行iret指令之前,cs 当前取值0x0008 ,含义是:CPU 当前的特权级(CPL)是0 级,当前的代码段由GDT 表中的1 号描述符指定。ss 当前取值0x0010 说明当前的栈段由GDT 表中的2 号描述符指定。这两个段的基址都是0。当前的栈顶指针esp(0x22ed0)靠近user_stack 数组的尾部(0x22f00)。对于move_to_user_mode()的原理,我们可以这样理解,这是第一次从核心态到用户态的切换,为了实现切换,操作系统伪造了一个栈帧,把事先伪造好的各寄存器的值都压入到栈中,压入栈中后核心栈的布局为:
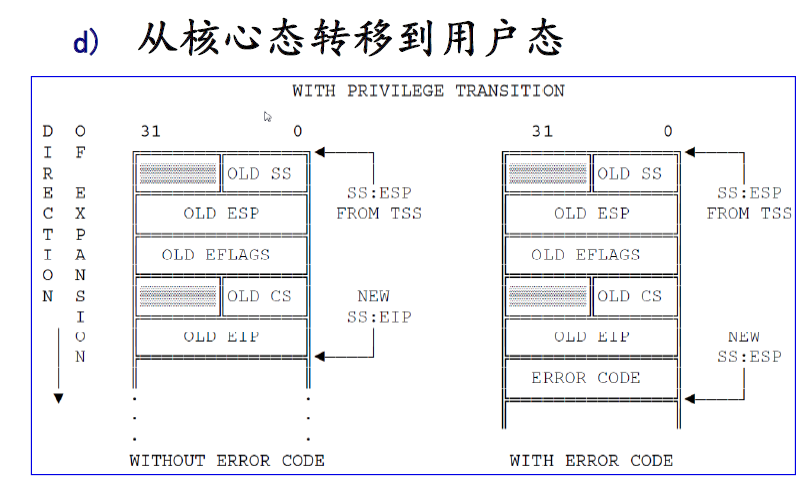
然后执行iret指令时,该指令便会将栈中事先准备好的数据,按照上图所示的结构赋值给相应的寄存器,具体的赋值为,首先将栈中的0x0f 赋给cs 寄存器,其含义是:将CPL 变为3 级,当前的代码段改为由LDT 的1 号描述符指定;然后将栈中的0x68ab 赋给eip 寄存器,再将标志0x0002赋给eflags 寄存器。我们已经分析过,当前LDTR 指向的LDT 实际上是init_task.task.ldt,对于init_task.task.ldt,其中1 号描述符的含义是:基址为0x0000,限长为640KB(=(0x0009f+1)*0x1000),DPL 为3级,代码段;2 号描述符的含义是:基址为0x0000,限长为640KB,DPL 为3 级,数据段。然后,CPU 会将栈中的0x17 赋给ss 寄存器、将0x22ed0 赋给esp 寄存器。ss 寄存器的新值的含义是:rpl 为3 级,段由LDT 的2 号描述符指定。使用的栈依然是user_stack,但现在是在用户态下使用该栈,用作用户栈,至此,user_stack才被真正用作用户栈。另外,代码段和栈段寄存器的值虽然变了,但它们实际的段基址并没有变,依然是0x0000。当然,最重要的是cs 寄存器的cpl 降到了3 级(用户级)。至此,进程0 已经由核心态降到了用户态,之后就在用户态运行,只有当它执行系统调用时或中断发生时,才会再切换到核心态。接下来的代码会给其他段寄存器赋值0x17,与ss 的新值相同,使其完全进入用户态。
上面所说的是系统第一次从内核态切换到用户态,所以采用了这种较为巧妙的伪造方式,实现了这个切换之后,也意味着现在已经实现了用户态和内核态的切换机制。那么,我们就来看下,在此之后,是如何实现用户态到内核态的切换的,参照blog——用户态和核心态(没有找到很详细的具体实现细节),从blog中我们可以知道,当满足3中方式中的一个,系统都会执行用户态到内核态的切换操作,就以系统调用为例,比如现在我执行一条int 0x80指令,由于没有找到很详细的细节,所以这里我从OS的角度出发(if i were a OS),自行脑补出相关细节,很可能有与实际不相符的地方,但苦于找不到资料,所以只能大胆猜测了。首先系统读到int指令,如果此时是用户态,那么系统就知道要切换到内核态了,这里明确一下,不管是用户态还是内核态,他都是属于同一进程的,一个进程可以有两个态,具体的切换过程为:1.从当前进程的描述符中提取其内核栈的ss0及esp0信息;2.借助两个通用寄存器保存当前的ss和esp;3.用ss0和esp0的值对ss以及esp寄存器赋值,此时就切换为内核栈了;4.再将此时的eflags、cs、eip和保存在通用寄存器中的用户态下的ss和esp按照iret返回指令要求的栈结构组织好;5.将根据中断号检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这时就转到了内核态的程序执行了。对于从内核态向用户态的切换,由于栈已经布置好,所以只需要一条iret指令即可返回用户态。
至此,我们已经完整分析了Linux 0.11 的启动、初始化过程,其中比较重要的姿势有段页式内存访问机制,进程的相关姿势以及OS对整个内存的布局。
还记得我们曾经添加的那个系统调用吗?接下来,为了描述进程以及讲解进程间的切换方便,我们要对源码进行简单修改,修改如下:在System_call.s中修改为:

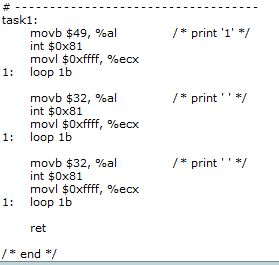
也就是注册了几个函数用于向屏幕输出字符,目的在于标识不同进程,然后在main.c中的修改为:
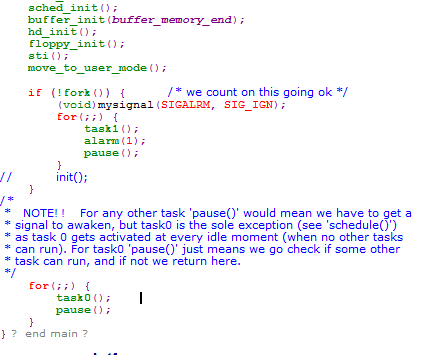
下面,我们就根据修改后的OS进行讲解。
上面已经将OS谈到了move_to_user_mode()处,根据上图修改的,我们知道,接下来就要去执行fork这个相当重要的系统调用了。首先,让我们对此时的内存布局有个整体的把握:
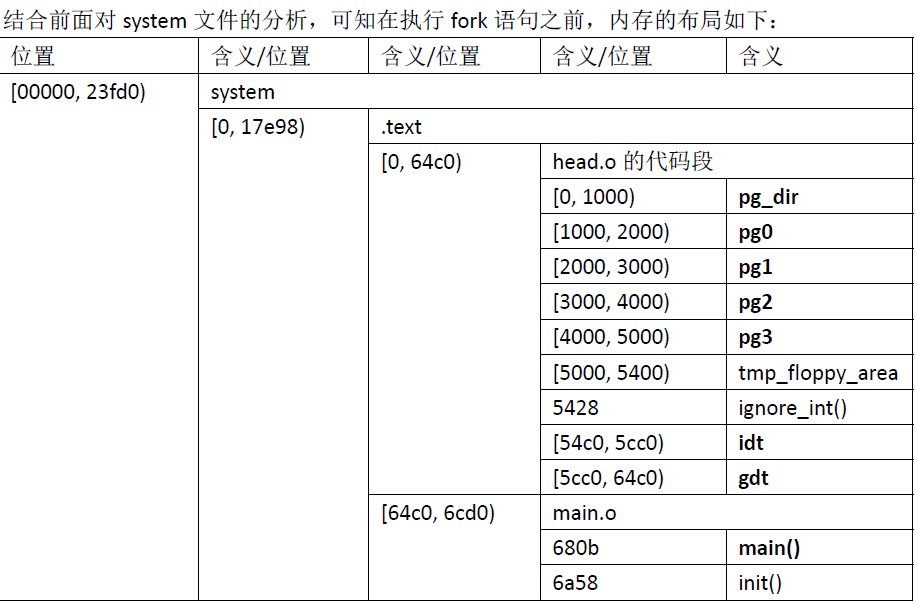
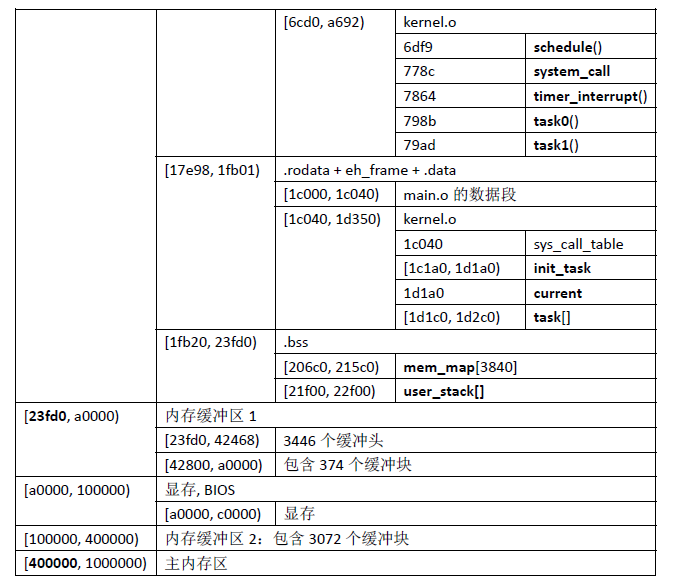
给出IDT对应的具体的中断处理程序:
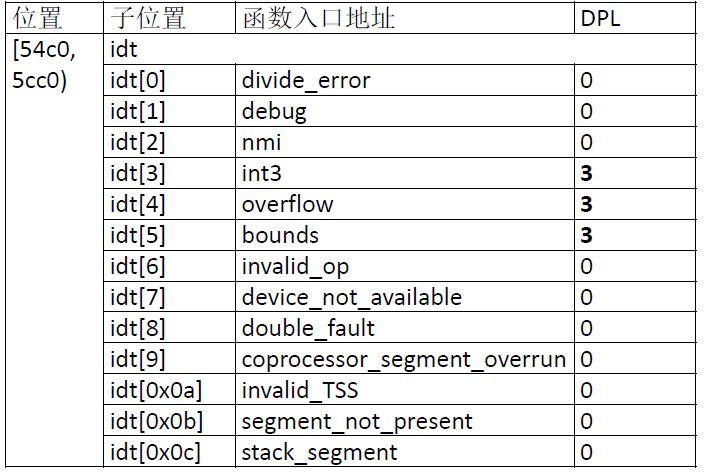
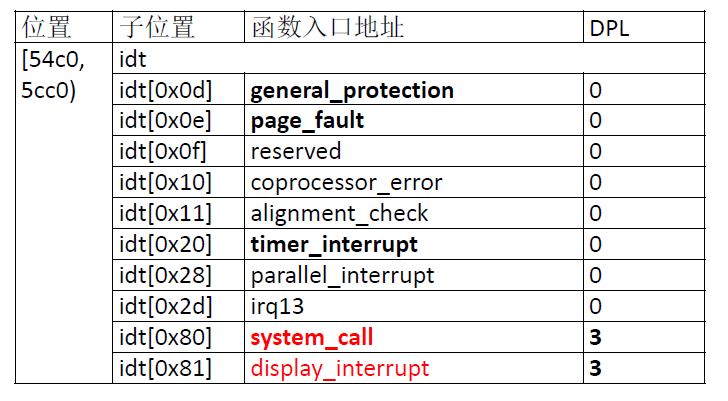
IDT中可以有中断门、陷阱门、任务门三种,对于三种门描述符如何区分,以及与其他描述符如何区分,给出blog——任务门,调用门,中断门,陷阱门 ,作为前面门描述符的补充。简单对当前IDT解释下,通过查看内存,我们可以知道IDT具体的16进制数据,下面就一些有特点的进行补充说明,其他的可借由门描述符的相关结构得出其对应的具体意义。中断描述符高长字中的“8f00”的含义是:段存在、dpl 为0、陷阱门。同时,有些描述符的处理函数入口地址为0x08:8213,指向的是函数reserved。前32 个中断描述符的设置是在main 函数的trap_init 函数中进行的。0x80 和0x81 号中断的处理函数入口地址分别为0x08:778c 和0x08:7970,分别对应函数system_call 和display_interrupt,这两个描述符中的“ef00”说明它们都是陷阱门、段存在、dpl 为3,因此用户程序可以直接调用这两个中断。函数display_interrupt 的功能是在屏幕上输出一个字符,通过直接访问显存来实现。
好,下面开始分析fork的执行过程。网上关于fork的介绍已经太多了,大家随意google一下就可以找到一大堆,这里就不在过多赘述,但这个fork真心很重要,一定要吃透,本来想把某前辈的分析直接搬来的,可是不让公开,我也没办法。。。
把下面分析要用到的几点说一下:1.fork系统调用在父进程中返回非零值,在新创建的进程中返回0值;2.新进程开始运行的地址设置为保存在tss中的eip 的值,我们知道通过fork新创建的进程在fork创建的过程中是将tss中的eip设置为int 0x80后面的一条指令的地址;所以第一次由0切换到1时执行的地址就是该地址。而以后进程在切换的时候,保存现场而存储在tss中的地址都是ljmp指令后面的那条指令的地址。因此每次进程切换回来都会从该语句执行,要从汇编的层面上去理解。注意:进程切换的本质是ljmp指令;3.不同进程切换时页目录地址不变。不同进程通过占据不同的线性地址空间来使用页目录中的不同页目录项,进而使用不同的页表,以达到进程隔离的目的。4.这里的进程拷贝只是创建了新的页目录项和对应的页表,创建的页表项指向相同的物理页面,也就是说这里能公用的就公用,比如代码段,需要不共用的就执行写时复制。5.我们把fork创建出来的进程称为1号进程,而原来的进程称为0号进程。
很容易分析出来,fork执行完后,由于是在0号进程中返回,所以返回值非0,if控制结构内的语句不会执行,而是去执行if后的语句,即执行task0函数,分析代码可知,0 号进程将执行一个无穷循环,但是在执行pause系统调用之前,也就是在执行task0的过程中,会发生时钟中断,这是第一个时钟中断。对于时钟中断函数,我们只看与调度有关的最后几行代码。
在时钟中断do_timer中,最后几行是对是否要执行schedule函数的判断,如果当前进程的时间片没有用完或者中断前系统处于核心态(直到2.4 版本Linux 内核都是内核不可剥夺的),则不进行调度,否则执行调度函数。执行完这个时钟中断后,0 号进程还剩14 个时钟中断周期(最近这个周期还没从counter 中减掉,因此现在显示counter 的值为15),且被中断前进程处于用户态,因此不会进行调度。进一步调试可以知道,该时钟中断发生在我们添加的函数中的一个loop循环中,因为循环执行时间较长,所以不难推断,第一次应该发生在此处,事实也是如此。
接下来,从task0返回后,就会执行pause系统调用了,函数sys_pause 会将当前进程的状态变为可中断等待状态,然后执行调度函数。对于调度函数schedule函数,它分为两部分,第一部分是对信号的一个判断,具体的处理过程是:检查每个进程,如果进程的alarm 时间已经超时,则置位SIGALRM 信号;如果进程有信号且当前处于可中断等待状态,则将其变为就绪态(TASK_RUNNING)。第二部分程序是选择一个就绪进程的进程号,然后完成进程切换。选择的算法是:选择所有就绪进程(0 号进程除外)中counter 值最大的那一个;如果没有一个就绪进程,就选择0 号进程;如果所有就绪进程的counter 值都为0,则给所有进程重新添加时间片(根据进程优先级确定各进程的时间片的长短),然后重新选择。
通过fork创建的1号进程在所有的创建工作都完成时,会将其置为就绪态,所以此次调度,1号进程被选中。然后,执行进程切换。
对于进程切换,即switch_to函数,给出源代码:

上面这段代码首先判断将要切换到的进程是否就是当前进程,如果是就跳过,否则把将要切换到的进程(进程下标为n)的进程控制块指针存入current、把该进程的TSS 选择子存入__tmp 的高长字,然后使用ljmp 指令跳转到进程n 的TSS,从而引发CPU 的现场切换,切换到进程n 执行。对于任务切换的关键,其实是ljmp指令,对于ljmp的具体细节,可以参考blog——linux0.11中switch_to理解
进程1被切换回来后,还记得当时fork进程1的时候在进程1的tss中存储的eip的值是什么吗?没错,就是int 0x80的下一条汇编指令的地址(从汇编的角度理解比C容易的多,对于C,还真不好描述它从哪开始执行),给出接下来的汇编指令:
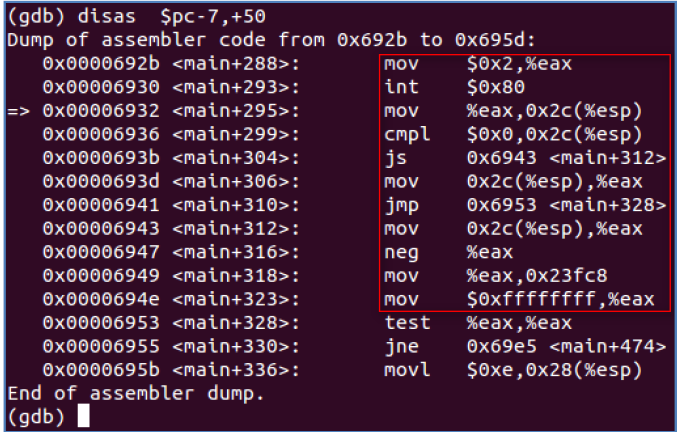
那么,根据进程切换多的相关姿势,进程1 被调度后的首次运行就从这条指令开始执行。对于当前指令mov %eax, 0x2c(%esp),可知这是要往一个变量中写,指令中的0x2c(%esp)对应到源代码中的局部变量res,可见当前指令试图给局部变量res 赋值,而后者是在栈中分配空间的。还记得前面的页表吗?我们在用fork创建1时,虽然1是复制了0的页表,也就是说1与0共享相同的物理页面,但是1对页面的权限是被修改了的,即1对于与0共享的页面是不具有写权限的,那么,执行这条指令就会触发异常喽。对应的异常处理函数是页故障异常处理函数。对于linux0.11,页故障异常处理函数非常简单,只有两个分支,缺页处理(do_no_page)或页写保护处理(do_wp_page),缺页是在当前进程访问的地址在页表中找不到相应的物理页帧时执行的操作,此时明显不属于这种情况,那么就会执行页写保护处理了(这里,你有没有发现,只要他能找到相应的物理页面,即使他不具有写权限,也会给他分配空闲页帧让他写,而不是报错啥的,可怕。。。),即执行所谓的写时复制机制。通过计算我们可以得出引发页故障的线性地址访问是0x4022edc,前面我们已知用户栈的栈顶指针esp 是0x22edc,加上段ss 的基址(可查LDT 表得知)就是0x4022edc,因此本页故障就是在试图往栈中写入一个数时引发的。对于do_wp_page函数,其中有一个个人认为还算经典的线性地址到物理地址转换的代码的具体体现:

大家可以结合前面介绍的线性地址转换为物理地址的步骤具体的针对这段代码来计算一下,对于体会位操作的强大很有帮助。函数调用un_wp_page 的参数是引发页故障的页表项的地址,经计算或调试可知引发页故障的页表项的地址为0xffe088(位于页表0xffe000 中),对于un_wp_page 函数,un_wp_page 函数会首先分配一个新页帧,然后修改页表项的值指向新页帧,并将原页帧的数据拷贝到新页帧中,新分配的物理页帧,1号进程对其是有写权限的。并会建立相应的页表项存储到页表中。然后就会从页故障处理函数中返回,这里需要提醒的一点是在处理完页故障后会再次执行0x6932 处的mov 指令,给局部变量__res 赋值。
接下来,程序就会正常执行了,还要提醒一点,通过上面的图可以知道,执行完写时复制后,接下来会对fork系统调用的返回值进行一个check,对应于C语言源代码的if,由于现在进程是1号进程,由fork的具体实现可以知道,此时的返回值是0,故if判断通过,进入if中执行,对于if中的语句,首先是设置alarm信号,对于alarm信号的处理是在调度函数中,设置完信号后的代码是一个死循环。我们接着来看OS的执行流程,这里我们只关心进程1和0之间的调度和切换,也就是说我们只分析一下函数:1.do_timer;2.schedule;3.sys_pause;4.do_wp_page。这里有必要说明一下,进程1是不会向显示屏输出任何东西的,因为有写时复制的存在,所以1在每次向显存中写东西时,都会写到由于写时复制而新分配的物理页帧中,并不会写到真正的物理显存中,所以1不会显示东西。
我们用调试的方法来看OS接下来的流程。切换回1后,首先发生时钟中断(第3次),此时的时钟中断并不会满足时钟中断中调度的条件,所以不会执行调度,此时1号还剩14个时间片。然后执行pause系统调用,进程1变为可中断等待状态并执行pause中的调度函数,由于1的等待状态,所以此次调度会选中0。接下来,由于1的等待状态,在1的信号到来之前,无论是时钟中断中的还是系统调用中的调度函数,当满足条件执行调度时,都只是0进程被迫调用0进程的尴尬局面。这里有一个细节不得不注意,那就是1进程在执行pause引发0的调度时,0进程在被调度回来是执行的第一条语句的位置,还记得进程切换的相关细节吗?切换的本质就是ljmp了,切换时会把eip的值给存储在当前进程的TSS中,然后从要切换的进程的TSS中取出eip,所以说0进程在被切换回来执行的第一条语句就是ljmp后面的那条指令了。此时还没有从系统调用中返回,然后从switch中返回,然后从pause中返回,还有一个细节,就是在从系统调用中返回时,会判断是否要进行调度,判断条件是只要当前进程不处于内核态就执行调度,处于内核态时,当当前进程的时间片为0时也会执行调度,所以说这里0被切换回来执行的第一次调度是由于0从系统调用返回时满足条件,从而引发的调度(主要想提醒下,分析时不要忘了此处有一个schedule)。然后时钟中断,然后系统调用,然后。。。
我们来看这种僵局如何打破,现在来分析下,进程1的信号设置的alarm 时间是1 秒,将在jiffies(时钟中断计数器)大于103 时被触发。通过调试验证当jiffies 为104 时开始处理上述alarm 设置,此时将设置进程1 的SIGALRM 信号位,接着将把具有信号的进程1 变为就绪态,接下来,在schedule中,第二部分代码就会选中进程1,然后就会切换到进程1执行了。
当进程1再次执行到pause时,进程1又会变为等待态,然后又会切换回0(因为没得选),直到进程1的alarm信号唤醒1之前,1号都会沉睡,每次满足条件执行调度时,都是0调度0的尴尬局面,就这样周而复始,生生不息。。。
